こんにちは、ヤフーのManagedValdチームです。
本記事ではYahoo!ショッピングなどさまざまなサービスで採用されているOSSのベクトル検索エンジン「Vald」の社内プラットフォーム化に見る、OSSを利用したKubernetes上でのas a Service開発のノウハウについてご紹介します。この記事で紹介する事例が、同じ課題を持つ皆様のお役に立てると幸いです。
※ 記事中のコードや構成図などは記事掲載のため一部省略しております。
なぜValdを社内プラットフォーム化したのか?
「Vald」は非常に高速かつ可用性の高い、OSSのベクトル検索エンジンです。
図: テキストでの近似ベクトル例(ベクトル検索ではさまざまな要素の距離に応じた検索などを行うことが可能)
そのメリットからVald利用ユーザー数も増え、近年はヤフーでもさまざまなサービスで活用されるようになりました。しかし一方で、ヤフーでValdを採用するサービスの増加とともに、ある課題が表面化していきます。
- Vald利用ユーザー個々にベクトル検索以外の要素技術習得コストがかかっている
- Valdは最新のKubernetes技術を積極的に採用するため、継続的に知識獲得を求められる
- ヤフー社内全体のVald運用/保守コストがVald利用ユーザー数に比例して増加する
- 初期構築、version up時の検証、トラブルシューティングなど一極集中できるコストもある
- それぞれが獲得した要素技術の知識や運用上での知見が共有されない可能性がある
私たちはこれらの課題を解決するために、OSSのVald開発チームとは別に社内専用のValdマネージメントチームを立ち上げました。そして社内Kubernetes上に展開したValdのベクトル検索機能だけを簡単に使える、一種のas a Serviceのような社内プラットフォーム「ManagedVald」を提供しています。
- “インフラを集約してコストもノウハウも一元管理し、エンジニアにはベクトル検索の美味しいところだけを体験してもらいたい”
- “多くのエンジニアがより簡単・便利にベクトル検索を利用できるようにして、ヤフーのAI活用のサイクルを早めたい”
全てはそのような目標のために日々工夫を重ねています。
同じようにエンジニア向けのas a Service開発を検討したい、Kubernetes上でOSSアプリケーションやHelmパッケージをプラットフォーム化したいという方々の参考になるよう、今回は私たちのプロジェクトで特に課題感のあった
- エンジニアのためのプラットフォーム開発とその課題
- 難しい設定ファイルを簡略化してOSS Vald利用のハードルを下げる
- Kubernetesの機能を使って任意の〇〇 as a Service (XaaS)を作る方法
- アプリケーションを安全に集中管理するための環境分離
- 公開Helm Chartに任意のコンテナを挿入し、中央集権的なアクセス認証認可を実現
について取り上げます。
エンジニアのためのプラットフォーム開発とその課題
冒頭で私たちの目標について触れましたが、その背景は Vald利用ユーザーの目的は何なのか? を追求した結果にありました。
まずVald利用ユーザー自身がエンジニアである、ということはそのエンジニアの方もまた別の何かを開発しているため、OSSアプリケーションやパッケージの利用はその開発を進めるための1つのパーツに過ぎないことは容易に想像できます。Valdについてもベクトル検索ができて高速に高精度な結果が返ってくれば良く、リソースチューニングやKubernetesのスペシャリストになるのが目的ではないはずです。
そうなるとベクトル検索機能以外のすべてをフルマネージドにして裏側は何も知らなくていいような世界観を目指したいところですが、これがエンジニア相手となるとなかなか思うようにいきません。なぜならVald利用ユーザー自身も開発を進める上でアプリケーションの設定を把握し、自由にカスタマイズする必要があるからです。
Valdには非常に多くのパラメータが存在あり、おそらく他のOSSアプリケーションにも同じことが言えると思います。私たちは既存設定ファイルの自由度を確保しつつ、可読性が高くて学習コストが低い理想的な設定ファイル化に挑戦しました。
次は技術的な要素を交えた具体的な取り組みについて説明します。
難しい設定ファイルを簡略化してOSS Vald利用のハードルを下げる
仕様を理解して設定内容を決める、というとごく基本的なようですが、その数が多ければ多いほど読み手に負担を強いることになります。
ValdはHelm Chartが公開されていてVald利用ユーザーの多くがこれを利用されているかと思いますので、まずはこの中の設定ファイルに当たるvalues.yamlを見てみましょう。(記事のためにかなり抜粋しています)
defaults:
time_zone: Asia/Tokyo
logging:
format: raw
level: info
logger: glg
server_config:
servers:
grpc:
server:
grpc:
interceptors:
- "RecoverInterceptor"
- "MetricInterceptor"
gateway:
lb:
enabled: true
rollingUpdate:
maxSurge: "25%"
maxUnavailable: "10%"
hpa:
targetCPUUtilizationPercentage: 50
ingress:
enabled: true
host: user01-namespace01.---.co.jp
gateway_config:
index_replica: 1
agent:
hpa:
enabled: false
rollingUpdate:
maxSurge: "1"
maxUnavailable: "1"
minReplicas: 3
maxReplicas: 3
name: vald-agent-ngt
ngt:
auto_index_check_duration: -1h
auto_index_duration_limit: -1h
auto_index_length: 1000
auto_save_index_duration: 30m
bulk_insert_chunk_size: 10
dimension: 128
distance_type: l2
object_type: float
enable_in_memory_mode: true
podManagementPolicy: Parallelこれだけでも、この全てのパラメータになんの意味があるのか、どういう作用を及ぼすのかに関心をもたせることは困難です。さらに、このvalues.yamlから生成されるValdコンポーネントをすべて把握し、メンテナンスしたいと考える人はあまり多くないでしょう。
そもそもこれらすべてを把握しないと何もできないということはないはずなので、まずは何も知らないVald利用ユーザーを想定して「最初の一歩」を踏み出すのに必要な程度に項目を絞り込んで、慣れてきた頃に関心のある項目を(ある程度)自由に扱えるようになっていく、そういう導線を引けると理想的です。
Custom Resourceで設定を抽象化
では私たちが社内プラットフォーム版として提供している設定ファイルを見てみましょう。
apiVersion: vald.vdaas.org/v1
kind: ValdRelease
metadata:
name: vald-cluster
spec:
gateway:
lb:
ingress:
host: user01-namespace01.---.co.jp
agent:
ngt:
dimension: 128
distance_type: l2項目が激減してdimensionやdistance_typeといったベクトル検索で主要な設定と必要最低限の項目だけが記載されています。極端な例ですが、これだけシンプルなら可読性も向上して利用のハードルも大きく下がるはずです。
それではなぜここまで設定を簡略化できたか、その仕組について説明します。まずこのファイルはHelm Chartの values.yaml に内容がよく似ていますが、ValdReleaseというCustom Resourceの一部です。ValdHelmOperatorというCustom Controllerとセットで動作するもので、どちらもOSSのValdに同梱されています。
この2つはVald運用において非常に有用で、ValdReleaseをデプロイするとKubernetesクラスタ内のValdHelmOperatorがhelm installのような動きを再現してValdコンポーネントを展開してくれます。またこの方法ではクライアント側にHelmの実行環境が必要ありません。つまりCustom Resourceを使うことで設定ファイルを自由に抽象化できるようになる上、Vald利用ユーザーをHelmなどの直接関係のない要素技術から解放できるというわけです。
KustomizeでVald利用ユーザーに必要な設定項目だけを分離
ここまではOSS Valdの標準的な仕組みに沿っているだけなのですが、もう一つ大事な工夫があります。
先程Custom Resourceの一部、と書きましたがもちろんこの設定だけではValdを構築できません。Custom Resourceを使うことで通常のKubernetesマニフェストと同様の取り扱いが可能になるので、私たちはこれをKustomizeで管理してシステム共通となる設定を1カ所に集約し、Vald利用ユーザーには個別に必要な部分だけを抽出して配布しています。
下記はKustomizeディレクトリ構造の例です。
.
├── bases
│ └── default
│ └── valdrelease #システム共通の設定を管理
│ ├── kustomization.yaml
│ └── vr.yaml
└── overlays
├── user01-namespace01 #個別の設定を分割。この部分だけをVald利用ユーザーに配布する
│ └── valdrelease
│ ├── kustomization.yaml
│ └── vr.yaml
└── user02-namespace01
└── valdrelease
├── kustomization.yaml
└── vr.yamlこのようにVald利用ユーザーに関心のない項目や見せる必要のない項目を隠蔽することで、視界に入る情報を減らして設定内容を把握しやすくする事ができます。
書かれていない内容に関してはVald利用ユーザーが積極的に関与する必要がないため学習・運用両面において大幅にコストカットができます。さらに理解が進んだ頃にはKustomizeの様式に従って設定の追加や上書きを可能にすることができるので、拡張性も担保できます。
管理者としてはValdのバージョンなど集中管理したい項目を掌握できるので、その点でも大きなメリットがあります。KubernetesでのXaaS開発においてこのようなマニフェストの抽象化はとても役に立ちます。
設定ファイル簡略化のポイント
ここまでをまとめると、設定ファイルの簡略化は以下の2点がポイントです。
- アプリケーション独自の設定ファイルはCustom Resourceでわかりやすく抽象化できる(Custom Controllerの開発も必要)
- Custom Resource化したManifestはKustomizeで取り扱えるため、利用ユーザー共通の設定と固有の設定を分離して管理・配布できる
通常のKubernetes利用ではあまりなじみがないCustom Resourceですがこれ自体はただのデータ群に過ぎず、Custom Controllerを用いてはじめて実態となるオブジェクトを生成できます。このCustom Controllerの開発に関してはOperator SDKというフレームワークがあり、これを利用すればValdHelmOperatorと同様の仕組みを開発できます。
この章ではHelm Chartを例に取って説明しましたが、応用次第ではいろいろなケースに対応できるのでぜひ検討してみてください。
Kubernetesの機能を使って任意の〇〇 as a Service (XaaS) を作る方法
あるアプリケーションを中央集権的に管理しつつ、不特定多数の利用ユーザーで環境を分離して使ってもらいたい、そういうユースケースは他にも存在すると思います。
シンプルに一つのKubernetesを複数の利用ユーザーで共有する設計(マルチテナント)なら
- 利用ユーザーごとにNamespaceを作成する
- IngressやServiceでエンドポイントを切る
- アプリケーションをデプロイする
これだけでおおよその部分をカバーできます。ですがこのままでは複数利用ユーザーの環境間でワークロードの高い処理が干渉しあうノイジーネイバー問題が懸念されるほか、対象ホストやIPアドレスを知っていれば誰でも別利用ユーザーのエンドポイントにアクセスできるセキュリティ上の問題も心配です。
またValdのようにHelmパッケージを使ってアプリケーション運用している場合はこういった特殊な事情への対応が難しくなります。Helm Chartでは定義されたパラメータ以外の変更が困難ですが、かといって一度Template出力して書き換えてしまうと今度はただのマニフェストファイルになってしまいHelmの便利な機能が利用できなくなってしまうからです。
そこでさらに工夫を重ね、この冒頭で触れた2点
- マルチテナントなKubernetes運用で利用ユーザー同士を安全に分離する方法
- 公開Helm Chartに任意のコンテナを挿入して中央集権的なアクセス認証認可を実現
について解説します。ちなみにHelm Chart以外でもKubernetesのマニフェストとして成立していれば同じテクニックが利用できます。
マルチテナントなKubernetes運用でVald利用ユーザー同士を安全に分離する方法
マルチテナント環境のKubernetesでノイジーネイバーを防止したい場合、どのような方法があるでしょうか。
一つの方法としてNamespaceにリソースクォータを設定して名前空間単位でリソースを制限する方法がありますが、Worker Node単位で見ると複数のVald利用ユーザー・不特定多数のPodがランダムに配置されてしまうのでこのケースの解決策としては十分ではありません。
そこでTaint/TolerationとnodeSelectorを利用して一連のWorker Nodeクラスタ単位でVald利用ユーザーのアプリケーションワークロードを分離する方法について説明します。
- NodeにラベルとTaintの付与
$ kubectl label nodes workernode-01 username=user-01 $ kubectl taint nodes workernode-01 username=user-01:NoSchedule --- # result apiVersion: v1 kind: Node metadeta: name: workernode-01 labels: username: user-01 spec: taints: - effect: NoSchedule key: username value: user-01 - PodのManifestにnodeSelectorとTolarationを設定
$ vi some-manifest.yaml --- apiVersion: v1 kind: Pod spec: # add nodeSelector: user: user-01 tolerations: - effect: "NoSchedule" key: "username" value: "user-01"
Nodeラベルの付与とnodeSelectorだけでは意図しないコンポーネントが混入される可能性があるためTaint/Tolerationを設定して防止しています。2. に関しては実際にはPodセットのオーナーであるDeploymentやStatefulset、Replicasetなどに記載するケースが多いと思います。
ちなみにTaintとは「汚れ」という意味で、Tolarationは「許容」です。Nodeについた特定の「汚れ」をコンポーネント側で「許容」する訳ですね。こうすれば同一Node内で複数のVald利用ユーザーがリソースを奪い合うことがなくなります。
ただし何かしらのHypervisorで動作するVMをNodeとして使用している場合は、Hypervisor上でVM同士のノイジーネイバーが発生する可能性があるため注意してください。
公開Helm Chartに任意のコンテナを挿入して中央集権的なアクセス認証認可を実現
これはKubernetesのDynamic Admission Controlという方法が適切です。
なんだか難しそうな名前ですが仕組みとしては単純で、認証認可を通過したkubeapi-serverへの操作(apply, deleteなど)をトリガーとして、マニフェストの内容を検証したり独自に変更を加えたりできます。
Kubernetesにapplyしたマニフェストはetcd上に書き込まれたタイミングで永続化されるのですが、そこまでにいくつかのステップを踏んでいると考えるとわかりやすいかもしれません。
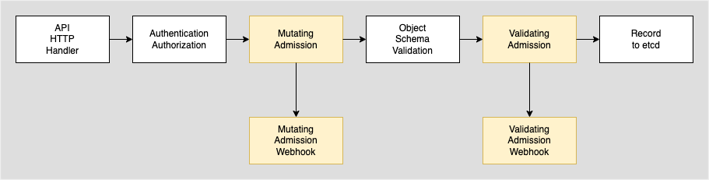
このMutatingAdmissionWebhookを利用すれば手元では加工できないHelm Chartや任意のCustom Controllerからのデプロイであっても、最終的に生成されるPodマニフェストに対して任意のアクセス制御用Sidecarコンテナを挿入することが可能です。
Valdの場合は最前段でリクエストを受けるvald-lb-gatewayというコンポーネントが存在するので、ここに対してRBAC用のSidecarコンテナを挿入し、本体がリクエストを受ける前にアクセス制御を行います。
またPod以外にもServiceやIngressも変更してポートフォワーディング情報を書き換えています。
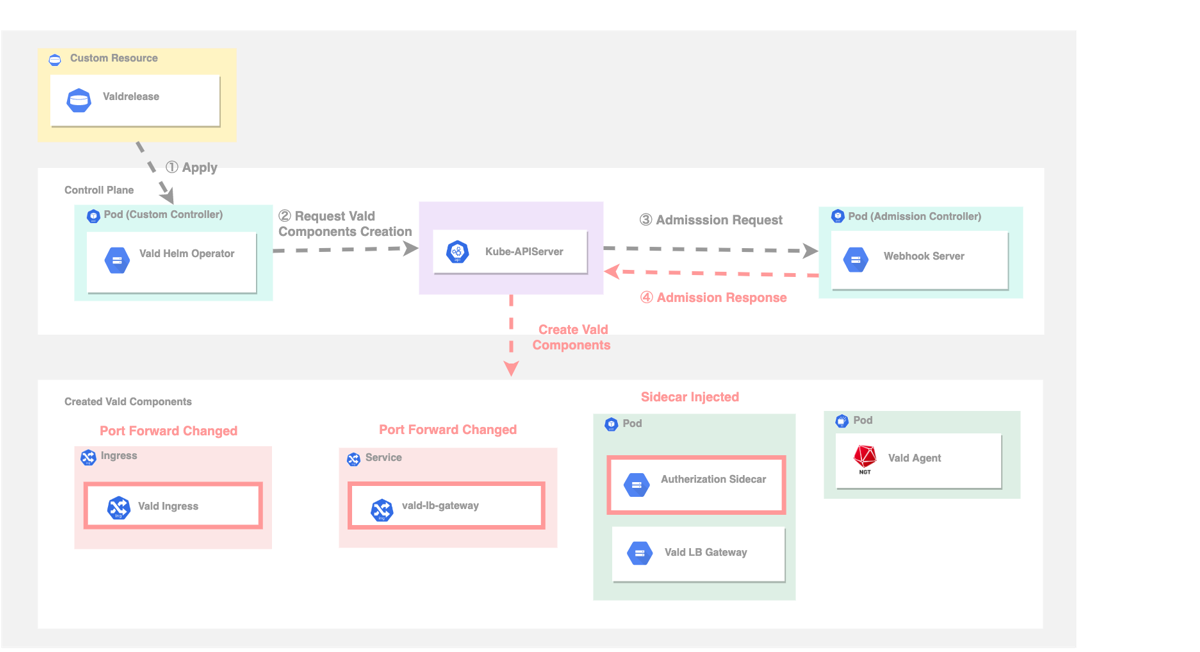
実装までの簡単な流れは以下のようになっています。
- マニフェストの内容を加工するためのwebサーバーとエンドポイントを作成する
- KubernetesのRBACでadmissionregistration.k8s.io/v1を有効にする
MutatingWebhookConfigurationに検知したいkubeapi-serverへの操作とオブジェクト、検知先である1のエンドポイントを記述する- 操作を検知すると
kube-apiserverが指定されたエンドポイントにマニフェストの内容を送信する - 1. のwebサーバーが変更した内容のマニフェストを
kube-apiserverに返却し、最終的に変更された内容のオブジェクトが生成される
1. で作成するControllerの内容もJSONを受けて加工して返すだけなのでそこまでハードルは高くありません。追加でValidatingWebhookと組み合わせて変更内容の検証なども加えるといいでしょう。Vald利用ユーザーに変更させたくない設定をここでブロックもできます。
ただし前項で紹介したValdHelmOperatorを利用する場合、ValdHelmOperator自身のReconciliation Loop(※)とAdmission Controllerの変更が競合してしまう可能性があるので要注意です。またこのDynamic Admission Controlを使うと、Kubernetesの宣言的な構成に変更が加わり理解が難しくなるので取り扱いには注意が必要です。
※ Custom Controllerが扱うKubernetesリソースの状態を観測してCustomResourceDefinition(Custom Resourceの定義)の内容と一致させる働き
プラットフォーム化の課題
ここまでプラットフォーム化の取り組みをお話しましたが、まだまださまざまな課題が残っています。
- Vald全機能の提供 / 継続的なバージョンアップ対応
- 別プラットフォームとの連携
- ユーザビリティの向上
他にもここで挙げたようなKubernetesの機能が環境によっては制限されていたり、Kubernetes自体のアップデートで予期しないトラブルに直面する可能性もあります。プラットフォーム化においてはそういったトラブルを一点に引き受けてあらゆる方向性で試行錯誤し、利用ユーザーへ安定したサービスを提供し続ける必要があります。
最後に
本記事ではヤフーでのOSSをプラットフォーム化する取り組みやKubernetesの応用方法についてご紹介しました。少しでも皆様のお役に立てる内容があれば嬉しいです。
OSSのベクトル検索エンジンValdはこれからも精力的に開発を続けていきますので、皆様のご利用やフィードバックを心からお待ちしております。
最後まで読んでいただきありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 山田 拓也
- プラットフォーム開発エンジニア
- 主にKubernetes周りの担当です。

- 谷口 正訓
- プラットフォーム開発・機械学習エンジニア
- 機械学習関連プロダクトの開発を担当しています。
-

- 西田 瑛絵
- プラットフォーム開発エンジニア
- Kubernetes基盤のシステム開発をしています。

- 安東 準星
- プラットフォーム開発エンジニア / Product Owner
- 最近趣味でFlutterを使ってアプリ開発をしています。



