こんにちは。ヤフーのディスプレイ広告(運用型)でデータサイエンス・機械学習エンジニアをしている高橋です。この記事では、機械学習における学習データ不足から生じるコールドスタート問題に対して、安定して学習・推論するための技術を紹介します。また、ヤフーのディスプレイ広告でこの技術を適用した事例をご紹介いたします。
コンバージョン予測の役割
みなさんの担当されているサービスにおいて、申込み完了率や商品購入完了率といったコンバージョンを高めたいシーンは多く見受けられるのではないでしょうか?あるユーザがコンバージョンしやすいか否かを推定できるようになると、よりコンバージョンしやすいユーザに優先的にサービスを提供できるようになります。特に、広告配信のようにコンテンツの配信そのものに費用がかかるケースでは、限られた予算の中でできるだけ効率的に配信することが求められます。このように、コンバージョン予測は費用対効果を最大化するためにも重要な役割を担っています。
(※パーソナルデータを含まない統計情報のみで予測します。ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
コールドスタート問題とは?
少量の学習データで機械学習を行う場合、大量の学習データで学習するのと比べて予測が安定しなかったり、そもそも学習が失敗する場合があります。コールドスタート問題とは、新規のユーザや新規のコンテンツなど、学習に必要な実績が十分にたまっていないために機械学習による予測が困難となる問題のことを指します[1]。
コールドスタート問題が生じると、新規のユーザや顧客に対する性能が悪化し、新規参入が難しくなり、市場の拡大が阻害される恐れがあります。また、新規コンテンツに対する予測が安定せずコンテンツが配信されづらくなる結果、学習データが蓄積されないという負の連鎖が生じることもあります。このように、コールドスタート問題は機械学習を利用するシステムにとって大きな課題となることがあります。
ディスプレイ広告においても同様の課題に直面しておりました。広告主が新規に作成された広告キャンペーンについては配信実績がたまっていないため、どのようなユーザがコンバージョンしやすいかの予測がうまくできませんでした。配信の仕組み上、学習データが不足した状態でも継続して配信できるため全く実績がたまらないことはありませんが、それでもたまるまで時間がかかることがあります。特に、高額商品のような購入頻度の少ない広告商品については、数日に1件しかコンバージョンを獲得できず、うまく予測できるようになるまで時間がかかるケースがありました。
コールドスタート問題を簡単に解決する方法として、対象以外の学習データを利用する方法があります。ディスプレイ広告においては、同じ広告主配下に作成されている別の広告キャンペーンの実績を利用する方法です。この方法であれば、学習を実施するための十分なデータ量を確保できますが、一方で対象の広告キャンペーンごとの個体差を反映できません。例えば、同じ広告主配下に作成されたキャンペーンであっても、ターゲットとしているユーザ層が異なる場合、それぞれのキャンペーンごとにコンバージョンしやすいユーザ層が異なります。もし複数のキャンペーンをまとめたデータで学習した場合、このような個体差を機械学習で表現することが難しくなってしまいます。
階層モデルとは?
階層モデルは、階層構造を持つデータに対して、階層ごとの個体差を表現するためのモデルです。階層構造を持つデータについての理解を深めるために、複数の学校で実施された共通テストの結果のデータを例に説明します。もしテスト結果のデータが、「学校」、「学年」、「クラス」、「生徒個人の情報」、「テストの成績」で構成される場合、このデータは階層構造として表現できます。
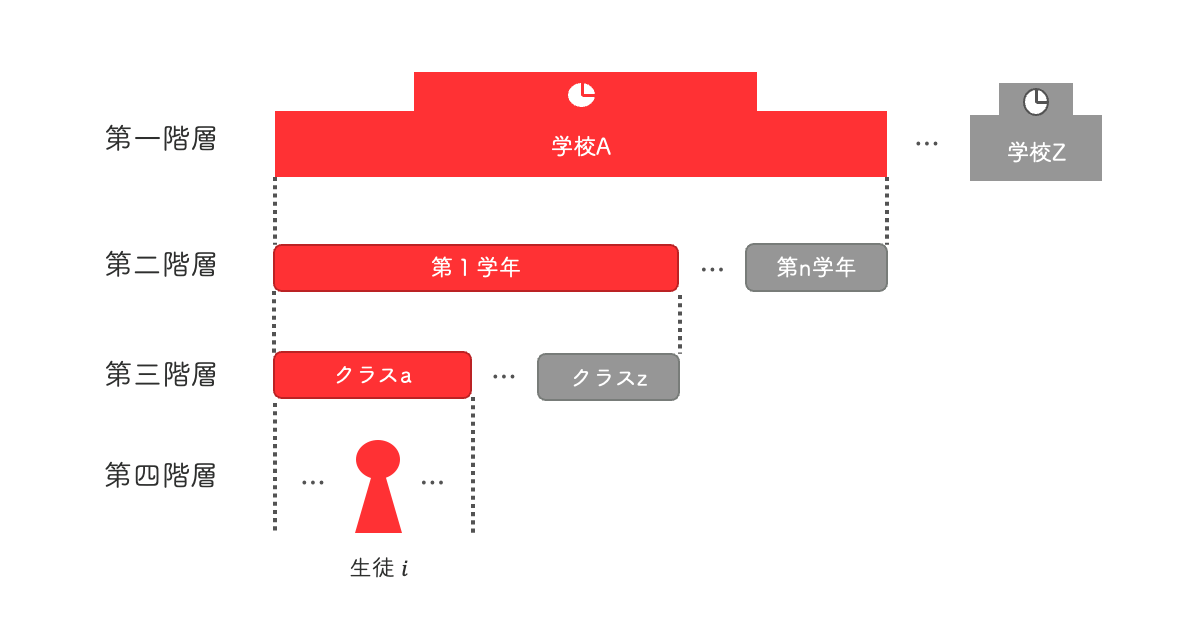
まず、ある生徒に着目したとき、その生徒が属する「クラス」が存在します。1つのクラスには通常複数の生徒が属するため、他の何人かの生徒も同じ「クラス」に属します。また、その「クラス」はいずれかの「学年」に属します。一学年に複数クラスが存在する場合、いくつかのクラスは同一の学年に属します。同様に、各「学年」はある「学校」に属することになります。このデータではこれ以上大きな粒度の情報がないため、第一階層を「学校」としてデータを4つの階層に分けることができます。
このとき、それぞれの学校や学年、クラスといった集団の個体差による効果を表現できるのが階層モデルです。例えば、ある学校は独自のカリキュラムによって、高学年の成績が比較的高い傾向にあったり、あるクラスは理系に特化することで理系科目の成績が高かったり、といった効果を表現できます。もちろん、生徒個人の情報が成績に及ぼす効果は大きいですが、それのみで表現しようとすると生徒の特徴による効果と、属する集団の効果を分離して評価することができない問題があります。また、学校や学年、クラスごとの個体差を生んでいる要因をすべて特定し、定量化することができれば理想ですが、現実的には原因をすべて網羅することは不可能なため、個体差を原因不明のまま扱うモデルが必要となります[2]。
このように階層ごとの集団の個体差を表現することは、コールドスタート問題の改善に役立ちます。例えば、ある学校のある学年に新規のクラスが設立されたとき、このクラスの生徒の成績はデータとしてまだたまっておりません。いわゆるコールドスタート状態です。しかし、新規以外のクラスのデータが十分にあるとき、新規クラスの属している学校の効果や、学年の効果を学習することができます。これにより、新規のクラスの生徒であっても、属している学校や学年の効果によって、生徒の成績を「ある程度」予測できるようになるのです。
階層モデルを利用したコンバージョン予測モデル
コンバージョン予測においては、「成績」の代わりに「コンバージョンしたorしなかった」のデータを扱います。各データは、どの広告主のどの広告設定に属するかによって階層化できます。まず、最も上の階層として広告主の広告カテゴリが存在します。これは、「旅行」や「食品」、「ファッション」といった広告商品のカテゴリの集団として定義されます。次に、広告主という階層が存在します。これは、広告を出稿していただいている広告主ごとの集団として定義されます。続いて広告キャンペーンの階層があり、その下に広告グループという階層が存在します。これらは広告の配信設定のグループとして定義されます。
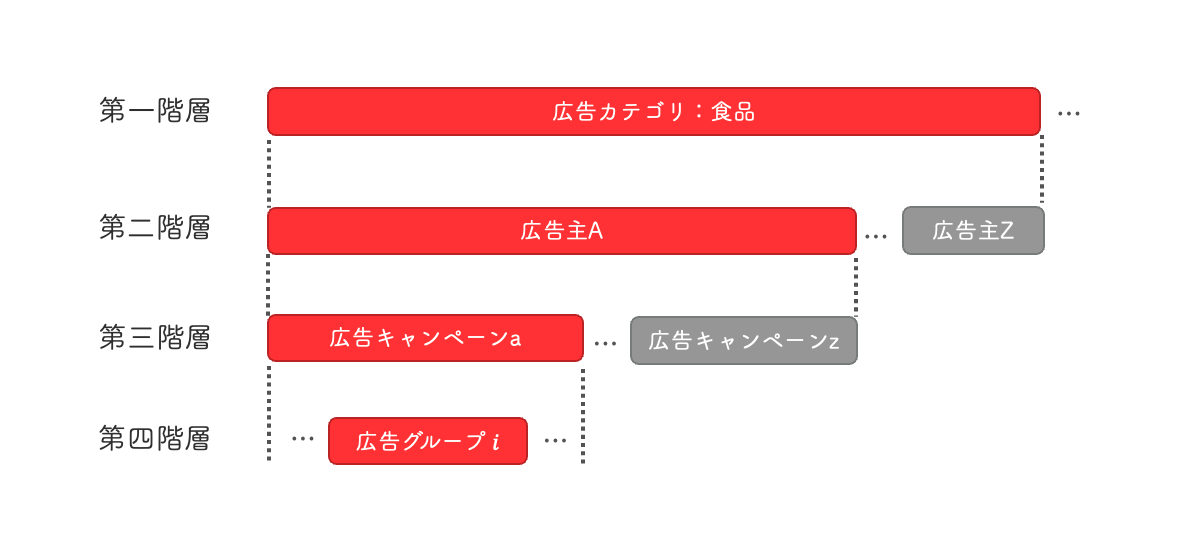
階層モデルではこれらの各階層の効果を表現できます。コンバージョン予測においては、各階層の効果をモデルパラメータとして表します。例えば、ユーザのリクエストのベクトル表現を x としたとき、コンバージョンするかしないかを表す y を回帰する式として、y=βx のようなものを考えられます(実際には非線形な関数を使ってもう少し複雑になります)。このとき β を、
β = 「広告グループ自身の特徴による効果」 + 「広告グループが属するキャンペーンによる効果」
のように与える効果ごとに分割します。また、同様に「キャンペーンによる効果」も、「キャンペーンが属する広告主の効果」を使って表す事ができ、「広告主の効果」は「広告主が属する広告カテゴリの効果」を使って表現できます。
以下では数式を使ってもう少し詳細な説明を加えます。上記で紹介した階層が与える効果は、数式としては次のような事前分布として定義できます。
$$ \begin{align} &\beta_{キャンペーン} &\sim& N(\beta_{広告主}, \sigma^2_{キャンペーン}) \nonumber \\ &\beta_{広告主} &\sim& N(\beta_{カテゴリ}, \sigma^2_{広告主}) \nonumber \\ &\beta_{カテゴリ} &\sim& N(0, \sigma^2_{カテゴリ}) \nonumber \end{align} $$注目すべき点は、各階層の効果の事前分布が、ひとつ上の階層の効果に依存する形で表現されている点です。これは階層事前分布と呼ばれており[2]、上の階層が下の階層に与える影響を表現することができます。ここで、分散のパラメータである$\sigma^2_{キャンペーン}$ や $\sigma^2_{広告主}$、$\sigma^2_{カテゴリ}$はハイパーパラメータとして設定しています。
我々は事後分布が最大となるもっともらしいパラメータの値が欲しいので、各パラメータについてMAP推定量を得るための学習を行います。対数事後分布を計算するとき、正規分布の事前分布がパラメータの荷重減衰の項として現れる性質を利用して、二乗正則化を利用した誤差関数を学習に利用しました。正則化係数として現れるハイパーパラメータについては、いくつかの組み合わせを探索することにより最適化しております。その結果、正則化係数が0付近でテスト誤差が最小になったことから、2022年11月現在は正則化なしでモデルを学習させております。
リリースの結果、データ不足の広告キャンペーンのCVRが改善
上記モデルを実際の広告配信に適用した結果、これまでCV実績のたまりにくかった広告キャンペーンの多くで広告効果の向上を確認できました。具体的には、データ不足によってコンバージョン予測がうまくいっていなかった複数の広告キャンペーンで、CVRが2.0%有意に向上しました。また、コンバージョン予測の予測精度指標としているAUCも5%ほど向上しました。
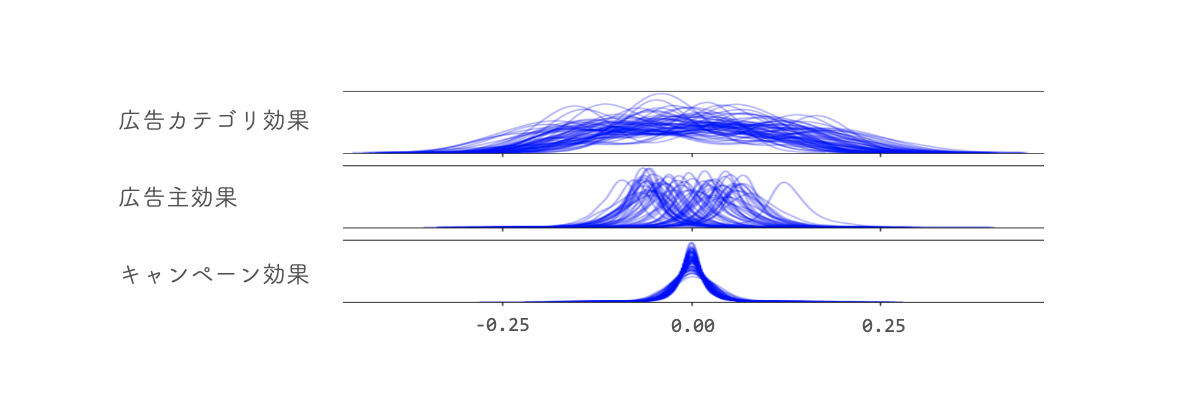
階層モデルで各階層の効果の大きさについて見てみると、想定通り上の階層の効果が予測に影響を及ぼしていることを確認できます。下図は、各階層ごとに効果の大きさを表しているヒストグラムです。各階層の効果は上の階層の効果との差を取ることで中心化しております。最も高い階層である「広告カテゴリ効果」の分散が大きく、カテゴリごとに違った効果を与えていることがわかります。また、逆に階層が下がるにつれて分散が小さくなっていることから、低い階層の方が効果の大きさが小さいことがわかります。このことは、キャンペーンそのものの実績が少なくとも、広告カテゴリや広告主の効果によってある程度予測できるという直観と一致しております。
おわりに
本記事ではコンバージョン予測を題材に、階層モデルでコールドスタート問題を解決する技術について紹介しました。ディスプレイ広告には膨大なデータが蓄積されており、またこれらを活用するための十分な基盤が整っております。データの価値を通じてより多くの人に便利を届けられるようなサービスにしていきたいと思います。
参考文献
- [1]: KULA, Maciej. Metadata embeddings for user and item cold-start recommendations. arXiv preprint arXiv:1507.08439, 2015.
- [2]: 久保拓弥. データ解析のための統計モデリング入門. 岩波書店. 2020.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 高橋 良希
- 広告データサイエンス
- ヤフー広告のデータサイエンスを担当しております。ベイズ統計や機械学習が好きです。色んなデータを数理的に解き明かしていきたいです。



