こんにちは! エンジニアの田中と池上です。
このたび、Yahoo! BEAUTYのiOSアプリにヘアスタイルシミュレーション機能を搭載しました。Yahoo! BEAUTYに投稿されたヘアスタイル写真から気になったスタイル、カラーが実際に自分に似合うかどうかをシミュレーションできる機能です。この機能はヤフーが独自に開発したAIで実現しています。
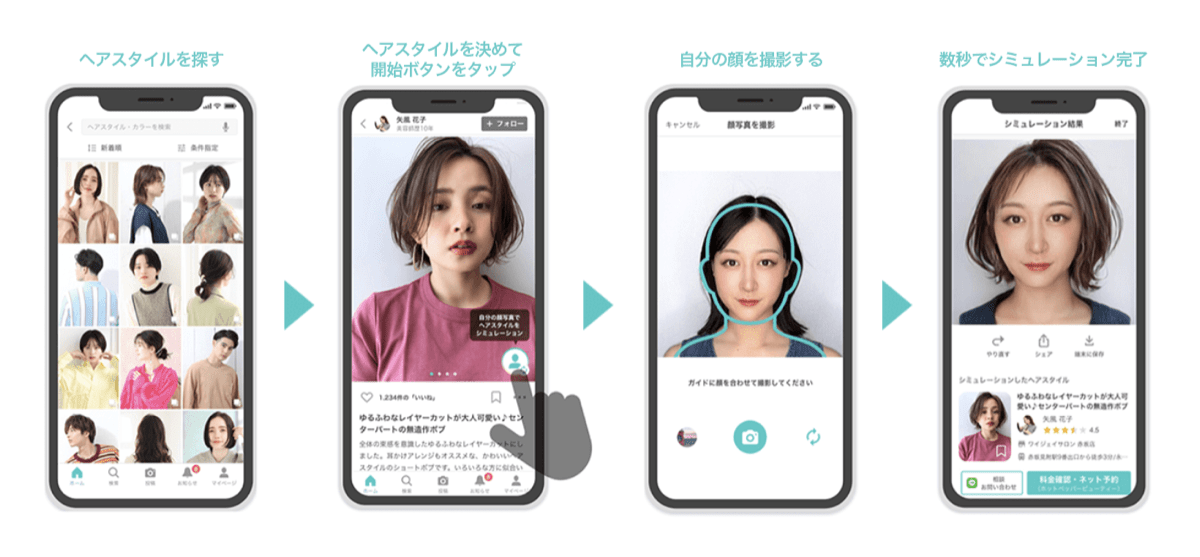
今回はCore MLとVisionといったiOSのフレームワークをフル活用することでこのAIをiOSアプリに搭載し、オンデバイスで機能を提供しています。これにより、みなさんの顔画像をサーバーに送ることなく、プライバシーに配慮した仕組みを実現しています。
具体的には下記の流れでシミュレーションの処理を行っています。
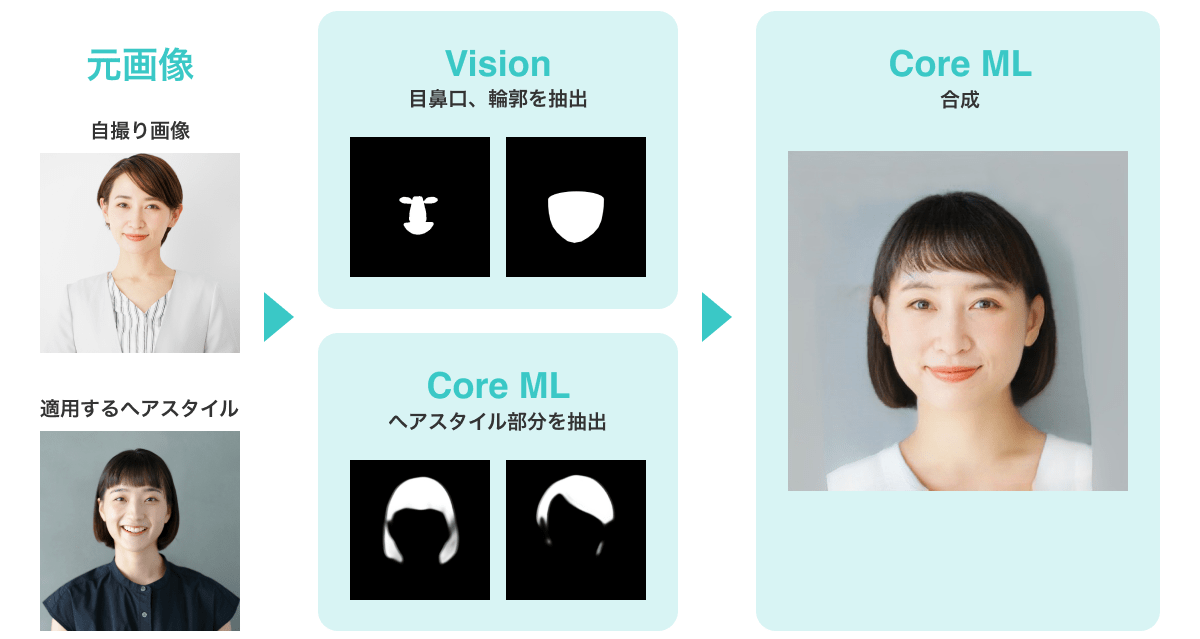
入力された画像から目や鼻といった人の顔のパーツがどこにあるのか、画像に映る人はどこを向いているのかといった画像処理をVisionで行い、その結果をもとにCore MLでシミュレーション画像の生成を行なっています。まずはCore MLを用いたシミュレーションの全体像から説明します。そして、実際にAIを動かすために必要なデータや処理をいかにVisionで行ったのかという順番で説明したいと思います。
Core MLについて
CTO室アプリ統括部の田中です。ここからはiOSアプリ内でのモデルの取り扱いについてご紹介します。
iOS上で機械学習モデルの推論を行うにはいくつかの方法がありますが、今回は Core ML を採用しました。Core MLはApple標準のフレームワークのため、別途ライブラリを導入する必要がなく、アプリの容量や運用コストの観点で優れています。また、最近では型を安全に扱うための機能が増えており、アプリのデグレ防止にもつながります。
開発の流れ
今回のモデル開発からアプリに組み込むまでの流れは下記の通りです。
- 機械学習フレームワークでモデルを作成 (Python)
- Core ML ToolsでモデルをCore MLに変換 (Python)
- アプリに組み込む (Swift)
今回はモデル開発者とアプリ側の実装者が異なっていたため、モデル周りのインターフェースについてのコミュニケーションが必要でした。アプリに組み込む際には、モデルに入力するデータやアウトプットの扱い方を知る必要があります。
そこで一連の流れがわかるJupyter Notebookを用意してもらい、それを見ながら、モデルに入力するためのデータを作成する前処理や出力データの取り扱いを確認していきました。この際にモデル開発者とアプリ実装者の専門分野を活かしてお互いにフィードバックし合うのが非常に重要だと感じました。
- モデルの出力結果を最適化するために必要な処理やアルゴリズムの共有
- Python上でCore MLのシミュレーションをする方法の共有
- Swiftから扱いやすくするためのモデルのインターフェースの提案
- モデルや入出力の説明をメタデータとしてCore MLモデルに書き込む方法の提案
- Model Package (mlpackage) 化の提案
このようなフィードバックによって、出力のクオリティを改善し、そしてアプリ側から扱いやすいモデルを構築できます。
Model Package (mlpackage) の利用
Xcode 13からCore MLモデルの新しい管理方法が増えました。それがModel Packageです。
Model Packageはモデルのメタデータや重み、学習パラメータを別々のファイルとして扱うことができます。それによって例えば、モデルのDescriptionを書き換えた時に、Gitの差分上で全く新しいモデルに差し替わったように見えてしまう問題を回避できます。メタデータはJSON形式となるため、非常に読みやすいです。
- "MLModelAuthorKey" : "--",
+ "MLModelAuthorKey" : "Yahoo Japan Corporation",参考(外部サイト):
- https://developer.apple.com/documentation/coreml/updating_a_model_file_to_a_model_package
- https://developer.apple.com/videos/play/wwdc2021/10038/
ここからは、アプリ側で工夫した点をいくつか紹介します。
工夫点:検証アプリの作成
モデルを何度も差し替えて確認することを考慮し、最初から対象のアプリに組み込むのではなく、ミニアプリとしてサンプルアプリを作って開発を進めていくようにしました。iOSアプリはビルドが遅くなりがちなので、さまざまなケースで特化したミニアプリを作るのはとても便利です。検証アプリにはSwiftUIを利用したため、簡単にUIを作成できました。
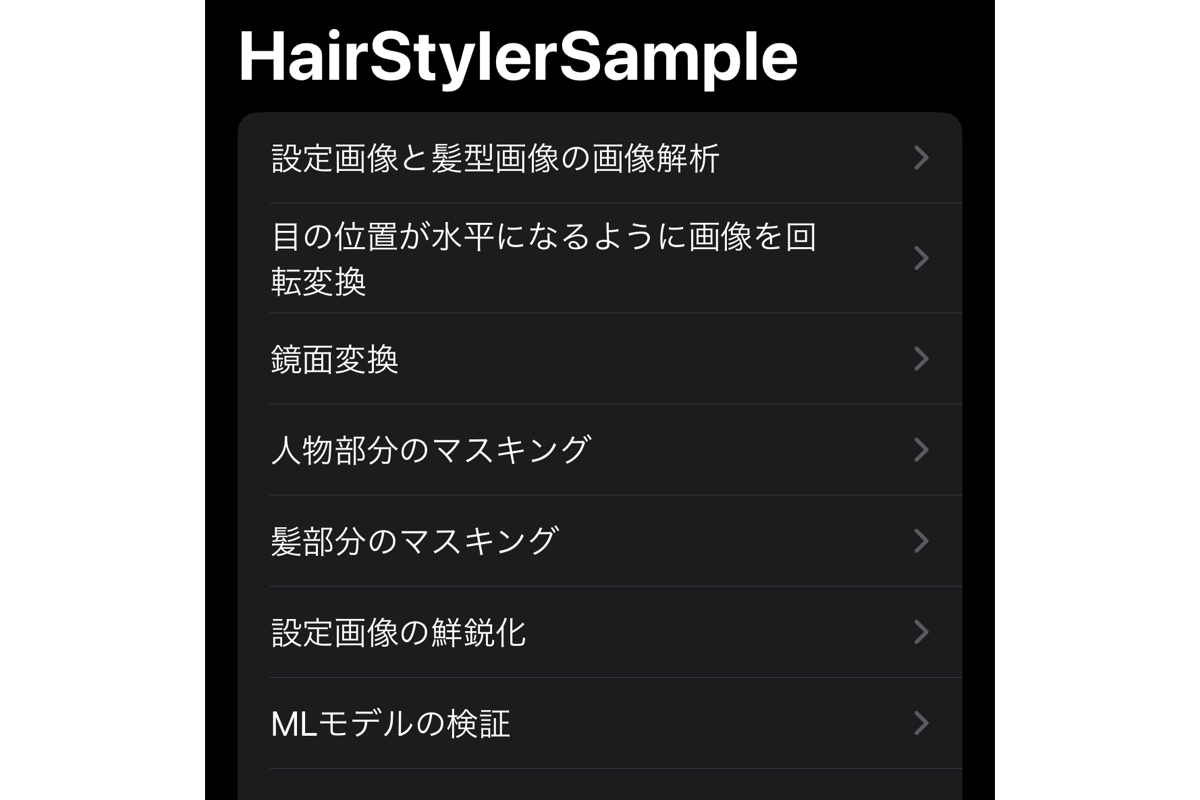
Visionについては次に紹介がありますが、モデルの入力前に多くの前処理が必要だったため、フェーズごとに出力を確認できるようにしました。これは各フェーズでの問題把握のためにかなり役に立ちました。
さらに、開発期間中は社内のアプリ配布のシステムを利用してこのサンプルアプリを配布することで、エンジニア以外の関係者でも簡単にモデルの品質チェックができるようになりました。
工夫点:高速なデータ変換
画像を扱うモデルの場合、Core ML Toolsの機能を使うと、Core MLの入出力を CVPixelBuffer として扱うことができます。
ただ、モデル側の都合などにより MLMultiArray や MLShapedArray として扱いたい場合もあります。その場合には各ピクセルの値を参照して配列に変換する必要がありますが、この時にAccelerateフレームワークを利用すると高速に処理できます。
// UIImageから正規化されたMLShapedArrayを作る
extension UIImage {
func makeGrayscaleArray() throws -> MLShapedArray<Float> {
guard let cgImage = cgImage, cgImage.colorSpace?.numberOfComponents == 1 else {
throw CustomError.invalidImage // グレースケールの画像以外は対象外にする
}
let buffer = try vImage_Buffer(cgImage: cgImage)
// CGImageからFloatの配列に変換
var floatPixels = vDSP.integerToFloatingPoint(
UnsafeMutableBufferPointer(
start: buffer.data.assumingMemoryBound(to: Pixel_8.self),
count: cgImage.width * cgImage.height
),
floatingPointType: Float.self
)
// 0〜255の値を0〜1に正規化
floatPixels = vDSP.multiply(1 / 255, floatPixels)
return .init(scalars: floatPixels, shape: [cgImage.height, cgImage.width])
}
}for文などでアクセスするよりもAccelerateを使うことでCPUのベクトルプロセッサを活用できるため、処理が速いです。
Vision について
CTO室アプリ統括部の池上です。ここからは本プロジェクトで採用しているVisionについてご紹介します。
Vision とは、画像解析処理を行うApple標準のフレームワークです。顔認識や文字認識など画像解析処理という分野において幅広く対応しています。今回開発したアプリでは、モデルへの入力として目、鼻、口などの顔のセマンティック情報が必要であるため、Visionから取得した顔認識の情報を元にそれらの入力データを生成しています。
顔の解析を行うにはいくつかの方法がありますが、プライバシー保護の観点から端末上のみで行う必要があるという点、また、Core MLと同様にしてアプリの容量や運用コストといった観点からVisionを採用するに至りました。
活用箇所
Visionは主に以下の処理に利用しています。
- 顔の正面判定
- 顔のセマンティック情報の取得
前者については、モデルの性質上正面から撮影した写真の方が精度が良くなるため、Visionの画像解析により顔の3次元の回転座標(row, pitch, yaw)を取得し、しきい値を設けることで正面判定を行っています。
後者についてはVisionにより顔のランドマーク情報を点群で取得し利用しています。ただし、今回はモデルに入力するデータとして顔の各パーツのセマンティック情報を白黒で表現した画像が必要であるため、取得した点群から領域を計算し生成しています。
また、モデルの学習に使用したデータはVisionを用いた入力を考慮しているわけではなかったため、セマンティック情報の範囲の期待値との違いがあり、そのままでは合成結果が期待と比べ劣化してしまう問題がありました。そこで地道な調整になりましたが、期待値である入力データを参考にしてVisionから生成した各領域情報に対して拡大・縮小などの処理を行うことで、最終的に期待通りの結果を得られるようになりました。
画像変換の効率向上
Visionでの処理の前後を含め、今回の実装では入力から合成出力までの間に内部では非常に多くの画像変換処理が行われています。
iOSでは画像クラスとしてUIImage, CGImage, CIImageなどがありますが、開発当初は各処理の実装を分担していたこともあり、扱いやすいようにUIImageを基本として実装を進めていました。その結果として各画像クラス同士の変換が随所に必要になってしまい、とても非効率な実装になってしまっていました。そこで、開発中盤に方針として内部の大半の処理をCIImageで統一するように修正し、処理の効率向上、コードの可読性向上を図っています。
CIImageは標準でGPUを用いた高速な画像処理が実行できること、実際に利用されるまで各処理を遅延して一括実行するように実装されていることから、今回のように画像の変換処理が多く必要な場合にとても有効です。
形式を統一することで、今後の更新で画像への処理を追加する場合も大きな影響を与えず、効率的に処理の追加を行うことができる状態になりました。
まとめ
いかがだったでしょうか?
今回はヘアスタイルシミュレーション機能をオンデバイスで実現するためにCore MLとVisionをフル活用しました。この2つのフレームワークを活用できれば画像を取り扱うAIの導入が可能になりますので、ぜひ参考にしてください。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 田中 達也
- iOSアプリ黒帯 / CTO室アプリ統括部
- アプリの技術課題の解決や新規技術の検証と開発をしています。
-

- 池上 幸次朗
- SWATエンジニア
- 普段はSWATという部署で、さまざまなサービスの開発に加わるなど全社を横断的にサポートする業務を行っています。



