こんにちは。Yahoo!検索で機械学習エンジニアをしている柴垣です。
Yahoo!検索では、ユーザーがホテル名や飲食店名などを検索したときに、ヤフー独自回答としてその拠点の付加情報も表示しています。この時、例えばユーザーが「青山グランドホテル」と入力してしまったとしても、正しい「THE AOYAMA GRAND HOTEL」の情報を表示できています。
この記事では、ユーザーの検索クエリの意図に合った拠点(ホテルや飲食店など)を検索するモデルをDeep Metric Learningで学習したベクトルを使った検索モデルにすることで精度を改善した事例を紹介します。
具体的には、主に以下のことについてコードを交えつつ紹介します。
- 改善したかった課題となぜそれをDeep Metric Learningで解決しようとしたのか
- 使っているモデルの構造と学習の際に工夫したこと
- そのモデルのプロダクト化はTensorflow Servingの使用により手軽に行えること
1 改善したかった課題となぜそれをDeep Metric Learningで解決しようとしたのか
1.1 改善前のモデルと課題
改善前のモデルはクエリと正解の拠点のペアに対してはラベルを1、ランダムにサンプリングした不正解の拠点のペアに対してはラベルを0としてランキング問題を学習タスクとしてLambdaMart[文献1] で解いていました。学習にはLightGBMを使っていました。特徴量はクエリと拠点側の情報(名前、名前の読み、住所)のマッチングスコアです。具体的には、クエリ/拠点側の情報を形態素解析やN-gramをアナライザーとして適用し、tf-idfやBM25を計算し、それを特徴量にしていました。
改善前のモデルで間違えてしまう目立ったパターンとイメージを数例紹介します。
表記ゆれに対応できない
| ユーザーの検索クエリ | 正解の拠点 | 改善前モデルでの検索結果 |
|---|---|---|
| 「山田グランドホテル」 | YAMADA GRAND HOTEL | 中田グランドホテル |
地名、ジャンル等に引っ張られて、拠点名指定を無視してしまう
| ユーザーの検索クエリ | 正解の拠点 | 改善前モデルでの検索結果 |
|---|---|---|
| 「石垣島 山田宿」 | 山田宿 | 中田宿 石垣島 |
| 「ラーメン 山田家」 | 山田家 | ラーメン 中田 |
地名、ジャンル等の指定を無視して、似たような拠点名の拠点を当ててしまう
| ユーザーの検索クエリ | 正解の拠点 | 改善前モデルでの検索結果 |
|---|---|---|
| 「ラーメン山田家 大阪」 | ラーメン山田家 (大阪にある) | ラーメン山田家 (大阪ではない) |
| 「山田 喫茶店」 | 山田 | 山田酒店 |
拠点側の情報にはないものを当てないといけないもの
| ユーザーの検索クエリ | 正解の拠点 | 改善前モデルでの検索結果 |
|---|---|---|
| 「東京駅近くのラーメン山田家」 | ラーメン山田家 八重洲口店 | ラーメン山田家 日本橋店 |
| 「乗馬体験ができるホテル 名古屋」 | 山田グランドホテル | 中田グランドホテル |
1.2 なぜDeep Metric Learningにしたか
改善前のモデルでも特徴量を頑張って作れば解決できないことはないとは思います。「地名、ジャンル等に引っ張られて、拠点名指定を無視してしまう」パターンでは、クエリを解釈するロジックを入れ、地名だということを理解して地名部分のみを拠点の住所とマッチングさせて、それ以外を拠点名にマッチングさせて、という具合で特徴量を作れば正解できる可能性があると思います。しかし、これは一例で全体的に精度を上げるにはさまざまなケースを人が考慮して特徴量を作っていく必要があるので大変です。
そこで、学習データ(クエリと正解拠点のペア)が大量にあることを生かして、DNN(Deep Neural Network)がよしなに学習してくれるのに期待しました。また、プロダクト化することを考えると遅くとも数百ミリ秒以内で応答する必要があるので、クエリと拠点側をそれぞれベクトル化してベクトル検索(内積によってランキング)するのが現実的だと思いました。そのため、そのようなベクトルを学習できるDeep Metric Learningで改善していくことにしました。
2 改善後のモデルについて
モデルはクエリ側と拠点側でそれぞれDNNを用意して、学習はクエリと正解拠点のベクトルは近づけるように、 クエリと正解以外の拠点は遠ざけるように行います。詳しくは後述します。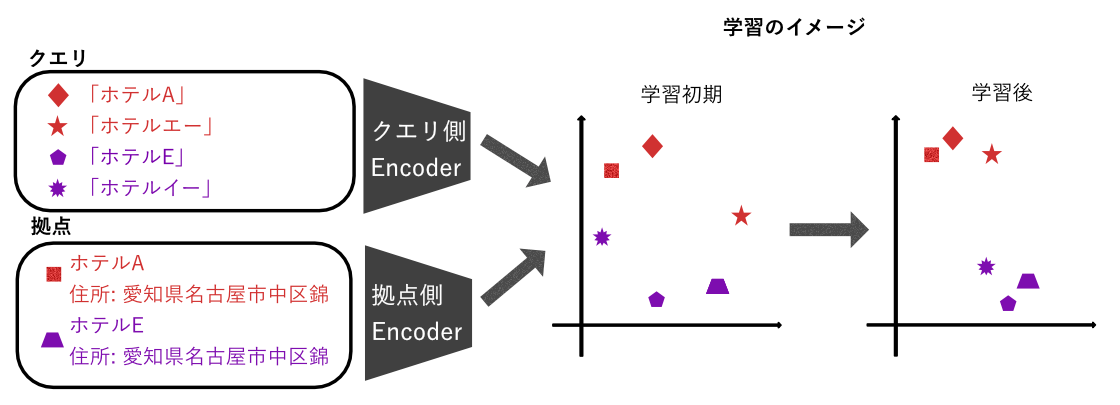
検索は、学習したモデルを使ってクエリ・拠点をベクトル化して、内積を計算して一番内積が大きい拠点を検索結果とします。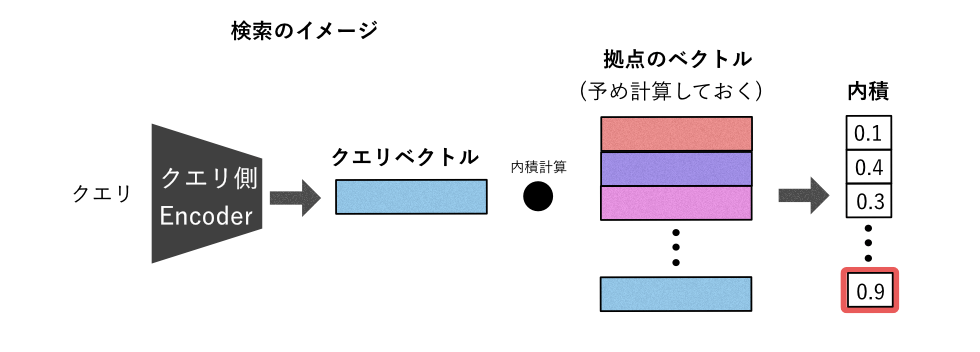
2.1 ベクトル化するモデル(Encoder)の中身
モデルはTransformer [文献2] のEncoder部分をメインで使っています。Transformerについては Tensorflowの公式チュートリアル Transformer model for language understandingがとてもわかりやすいです。
具体的には、TransformerのEncoder部分を以下のように使っています。
- 文字列(クエリや拠点側の情報)をSentencePiece [文献3] によってToken ID列化
- Embeddingレイヤーに入れる (それに、次元数の平方根をかけてpositional encodingを足す)
- TransformerのEncoderLayerを複数回通す
- GlobalAveragePooling1Dを通して、Token方向で平均を取る
- point_wise_feed_forward_networkを通して、最後にL2正規化する
コードを示すと、以下のようになります(Tensorflowのversionは2.4を使っていました)。
import tensorflow as tf
# Token ID列化とTensorflowの公式チュートリアルで定義されている関数やクラスは省略しています
class TransformerEncoder(tf.keras.models.Model):
def __init__(self, num_vocab, dim_embedding, dim_hidden, num_heads, num_layers, maximum_position_encoding):
super().__init__()
self.dim_embedding = dim_embedding
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(num_vocab, dim_embedding)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.dim_embedding)
self.enc_layers = [EncoderLayer(dim_embedding, dim_hidden, num_heads) for _ in range(num_layers)]
self.aggregate = tf.keras.layers.GlobalAveragePooling1D()
self.ffn = point_wise_feed_forward_network(dim_embedding, dim_hidden)
def call(self, x):
seq_len = tf.shape(x)[1]
mask_for_attention = create_padding_mask(x)
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.dim_embedding, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
for i in range(self.num_layers):
x = self.enc_layers[i](x, mask_for_attention)
x = self.aggregate(x)
x = self.ffn(x)
return tf.nn.l2_normalize(x, -1)2.2 学習方法
学習データは クエリと正解拠点のペアで持っており、クエリと拠点のペアを複数個サンプリングし(ミニバッチ)、Metric Learning の損失関数を使って損失を計算し最適化してきます。損失関数内ではミニバッチ内にあるクエリと拠点のすべての組み合わせで損失を計算しています。損失関数はMetric Learningの損失関数の中でも基本的なContrastive Loss [文献4] を使っています。Contrastive Lossはとてもシンプルで、クエリと正解拠点のペアであれば内積が大きくなるように1-内積を損失に、クエリと不正解拠点のペアであれば内積が一定値以下になるように内積が一定値より大きければその内積を損失にします。
コードを示すと以下になります(ミニバッチ内のすべての組み合わせの損失を計算しています)。
def contrastive_loss(
query_vectors, query_labels, spot_vectors, spot_labels, margin
):
"""
query_vectors, spot_vectors: それぞれクエリと拠点のベクトルでshapeは[ミニバッチ数, ベクトルの次元数]です
query_labels, spot_labels: それぞれクエリの正解拠点のラベル、拠点のラベルでshapeは[ミニバッチ数] です
margin: マージン(ハイパーパラメータ)です (例えば 0.7)
"""
similarity_matrix = tf.linalg.matmul(query_vectors, spot_vectors, transpose_b=True)
query_labels_expand = tf.transpose(tf.repeat([query_labels], repeats=tf.shape(spot_labels)[0], axis=0))
positive_mask = tf.equal(query_labels_expand, spot_labels)
negative_mask = tf.logical_and(tf.logical_not(positive_mask), tf.greater(similarity_matrix, margin))
return (
tf.reduce_sum(1 - tf.boolean_mask(similarity_matrix, positive_mask))
+ tf.reduce_sum(tf.boolean_mask(similarity_matrix, negative_mask))
) / tf.cast(tf.shape(query_labels)[0], tf.float32)Metric LearningにはContrastive Loss以外にもたくさんの損失関数がありますが、このケースでは [文献5] で報告されているようにContrastive Lossでも十分精度が出ました。
Deep Metric Learningの研究ではよく画像検索がタスクとして取り扱われています。画像検索だとクエリと検索対象どちらも画像なので、ベクトル化するモデルをそれぞれ用意せず共有するのが一般的だと思います。今回のケースでは検索クエリと拠点側の情報は同じではないため、クエリ×拠点のペアの組み合わせだけではなく、クエリ×クエリ、拠点×拠点の組み合わせに対しても損失を計算し最適化するように工夫しています。
それだけではクエリと正解拠点の学習データに登場する拠点しか学習されないので、クエリ×ランダムサンプリングした拠点、ランダムサンプリングした拠点同士の組み合わせに対しても損失を計算しています。ミニバッチ数とランダムサンプリングする拠点の数はGPUのメモリが許す限り大きくしたほうが精度がでました(ミニバッチ数は4096、ランダムサンプリングする拠点の数は28672に設定しています)。
学習の1stepをコードで示すと以下になります。
def train_step(
query_encoder, spot_encoder, optimizer,
query_token_ids, query_labels,
spot_token_ids, spot_labels,
ex_spot_token_ids, ex_spot_labels,
):
"""
*_encoder : Encoder (例えば、TransformerEncoder)
optimizer: 最適化アルゴリズム (例えば、tf.keras.optimizers.Adam)
*_token_ids: クエリ/拠点の入力をSentencepieceでTokenID列化したもの (shape=[ミニバッチ数, Token ID列の最大長])
"""
n = tf.shape(spot_token_ids)[0]
with tf.GradientTape() as tape:
query_vectors = query_encoder(query_token_ids, training=True)
spot_vectors = spot_encoder(spot_token_ids, training=True)
ex_spot_vectors = spot_encoder(ex_spot_token_ids, training=True)
qs_loss = contrastive_loss(query_vectors, query_labels, spot_vectors, spot_labels)
qq_loss = contrastive_loss(query_vectors, query_labels, query_vectors, query_labels)
ss_loss = contrastive_loss(spot_vectors, spot_labels, spot_vectors, spot_labels)
qe_loss = contrastive_loss(query_vectors, query_labels, ex_spot_vectors, ex_spot_labels)
ee_loss = contrastive_loss(ex_spot_vectors[:n], ex_spot_labels[:n], ex_spot_vectors, ex_spot_labels)
loss = qs_loss + qq_loss + ss_loss + qe_loss + ee_loss
variables = query_encoder.trainable_variables + spot_encoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss学習はヤフー社内のAIプラットフォーム上に立てたJupyterHubで行っています。簡単にGPUリソースを確保できてとても快適です。
3 どのようにプロダクト化したのか
主にクエリ/拠点をベクトル化するところと、内積を計算するところをどのようにプロダクト化したかを紹介します。
3.1 ベクトル化はTensorflow Servingを使うことで簡単にプロダクト化
Tensorflowではモデルに文字列の正規化やSentencePieceによるToken ID列化といった前処理も含めてTensorflow Serving(TFS)でServingできます。つまりTFSの前段で別のAPIを構築して、前処理する必要がないということです。
具体的には以下のように直接TFSにリクエストするだけで、前処理とモデルの推論を行えます。
> curl -d '{"instances": [{"query": "品川プリンスホテル"]}' -X POST [TFSのURL]
{
"predictions": [[-0.00571914762, 0.097049661, -0.0528469719, -0.0421413593, ...]]
}簡単にそのようなServing可能なモデル(SavedModel)の作り方について紹介します。Tensorflow Textのおかげで前処理を含めたSavedModelを作成できます。
import tensorflow_text as tf_text
class TextEncoder(tf.keras.Model):
def __init__(self, encoder, tokenizer_path,max_sequence_length):
super().__init__()
self.max_sequence_length = tf.constant(max_sequence_length, dtype=tf.int64)
self.tokenizer = tf_text.SentencepieceTokenizer(
encoder=open(tokenizer_path, "rb").read()
)
self.encoder = encoder
def call(self, x):
# 前処理
x = tf.strings.regex_replace(x, " +", " ")
x = tf_text.normalize_utf8(x, "nfkd")
# Token ID列化
x = self.tokenizer.tokenize(x).to_tensor(shape=[None, self.max_sequence_length])
# モデル推論
return self.encoder(x, training=False)
query_text_encoder = TextEncoder(
query_encoder, "Sentencepieceモデルのファイルパス", max_sequence_length=15
)
@tf.function(input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="query")])
def predict_fn_query(query):
output = query_text_encoder(query)
return {"vector": output}
signatures_query = {
'serving_default': predict_fn_query.get_concrete_function(),
}
tf.saved_model.save(query_text_encoder, "saved_modelの保存先ファイルパス", signatures_query)ヤフー社内ではそのように作成したSavedModelで推論APIを構築できるマネージドサービス(CuttySark)が提供されているので、それを利用して推論しています。
3.2 内積を計算するところはABYSSを使用
ヤフー社内では ABYSS(Solr Cloudを利用した検索の共通基盤)を使うことで、利用者は低コストで検索エンジンを利用できるようになっています。
そしてABYSSではヤフー独自の内積を計算するプラグインが提供されているので、ABYSSを利用するだけで内積ランキングを実現できます。
また、宿泊拠点、飲食拠点、それ以外の拠点の検索エンジンを別々に作っており、宿泊・飲食は比較的拠点数が多くないので愚直にクエリとすべての拠点の内積計算しても十分速いのですが、それ以外の拠点はすべての拠点で内積計算してしまうと時間がかかりすぎてしまうため、ABYSSで提供されている近似最近傍探索プラグインを利用しています。
今回のケースでは要件的にABYSSを使って内積を計算していますが、拠点の更新頻度が低くて拠点のベクトルがメモリに乗るのであれば、クエリのベクトル化と内積ランキングをまとめてTensorflow Servingでやるという選択肢が実装コストは低いと感じています。(参考: Tensorflow Recommendersのチュートリアル Efficient serving)
4 モデル改善でうまくいったこと・いかなかったこと(おまけ)
最後にモデルの改善に効いたものと効かなかったものを紹介します。
4.1 うまくいったこと
- Transformerのpositonal encodingの代わりに双方向LSTM [文献6] を入れる
- 多少ではありますが、精度が上がりました。
- 損失関数を Proxy Anchor Loss [文献7] のようなものにする
- Proxy Anchor Lossは2020年に発表された損失関数です。Contrastive Loss から Proxy Anchor Loss にすると精度が多少上がりました。Proxyといっていますが実際はProxyを使っておらず、Proxyを拠点側のベクトルに置き換えたものを使っています。
- Hard Negativeを入れて学習する
- ミニバッチを構成するクエリと正解拠点のペアはランダムにサンプリングしています。一度そのようにして学習したあと、そのモデルを使って検索結果上位数件(Hard Negative)を取得しミニバッチに加えてさらに学習すると精度が上がりました。その際、クエリ側のモデルと拠点側のモデルのパラメータを同時に更新してしまうと逆に精度が下がってしまったのですが、拠点側のパラメータは固定しクエリ側だけ学習するとことでうまくいきました。
4.2 うまくいかなかったこと
- TransformerのLayer数を増やす
- 最終的にはクエリ側は2層、拠点側は1層になりました。Layer数を増やすと、ミニバッチの数を減らさないとOOMになってしまうのでLayer数とミニバッチ数がトレードオフになってしまうというのもありましたが、単純に同じミニバッチ数でLayerを増やしてみても精度は上がりませんでした。学習データがもっと膨大にあれば違う結果になるのではないかと思っています。
- 拠点の情報の使い方を工夫する
- 拠点側の情報は、拠点名と住所を結合してモデルの入力にしていますが、拠点名用のモデルと住所用のモデルを別々にしそれぞれのモデルの出力をconcatして全結合層を通すものを試してみたのですが、精度は上がりませんでした。
5 おわりに
上記の検索モデルの改善によって、検索の品質指標を保ったまま独自回答のクリック数を増やすことができました。また、必要なときに素早く環境を構築できるABYSSやAIプラットフォームなどの社内のプラットフォームのおかげで、最初のA/Bテストは3ヶ月で行えました(自分1人が1ヶ月モデルの検証の後、3人チームでモデル改善とプロダクト化を2ヶ月)。
まだまだ独自回答を表示できないクエリがあったり、意図とは違った拠点を表示してしまったりという課題はあるので改善を続け、ユーザーの皆様に使いやすい検索を届けられたらと考えております。
参考文献
- [文献1] Burges, Christopher JC. “From ranknet to lambdarank to lambdamart: An overview.” Learning 11.23-581 (2010): 81.
- [文献2] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
- [文献3] Kudo, Taku, and John Richardson. “Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing.” arXiv preprint arXiv:1808.06226 (2018).
- [文献4] Hadsell, Raia, Sumit Chopra, and Yann LeCun. “Dimensionality reduction by learning an invariant mapping.” 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06). Vol. 2. IEEE, 2006.
- [文献5] Musgrave, Kevin, Serge Belongie, and Ser-Nam Lim. “A metric learning reality check.” European Conference on Computer Vision. Springer, Cham, 2020.
- [文献6] Schuster, Mike, and Kuldip K. Paliwal. “Bidirectional recurrent neural networks.” IEEE transactions on Signal Processing 45.11 (1997): 2673-2681.
- [文献7] Kim, Sungyeon, et al. “Proxy anchor loss for deep metric learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 柴垣 篤志
- Yahoo!検索 機械学習エンジニア
-



