こんにちは、Technical Yahoo の中谷です。
今回は、ヤフーからオープンソースとして公開している RBAC(Role Based Access Control)システムである K2HR3 を使い、K2HDKC(分散KVS)を Database as a Service(DBaaS) として公開しましたので、ご紹介します。
K2HR3 および K2HDKCは、ヤフーがオープンソースとして公開する AntPickax プロダクトです。
Database as a Service(DBaaS)としての K2HDKC(分散KVS)
K2HDKC(k2hash based distributed kvs cluster)は、ヤフーオリジナルの 分散KVS システムです。
このK2HDKCを、Database as a Service(DBaaS) として簡単に構築、利用できるようにいくつかのツールを準備しました。
まず、Database as a Service(DBaaS)のサービスとして動作するための IaaS(Infrastructure as a Service)環境として、OpenStackおよびKubernetesの利用を想定しました。
現在、OpenStackおよびKubernetesのIaaS環境で、K2HDKCをDBaaSとして提供できましたので、ご紹介いたします。
OpenStack対応は、2種類の方法を提供します。
一つは、Trove へ組み込み、Dashboard(GUI)から操作するTrove版と、もう一つはコマンドラインでOpenStack上にK2HDKCを展開するCLI(Command Line Interface)ツールです。
また、Kubernetes対応は、CLI(Command Line Interface)ツールで提供します。
簡単に、それぞれの特徴を以下に示します。
Trove版 K2HDKC DBaaS
TroveのDashboard(GUI)から操作できるdatabaseの一つとして、K2HDKCを組み込めます。
K2HDKCクラスターの構築・破棄・スケール・バックアップなどの操作を他のdatabaseと同様にTroveから操作できます。CLI版 OpenStack対応 K2HDKC DBaaS
Trove版と同等の機能をTrove(Dashboard)を使わず、CLIツールから操作できます。CLI版 Kubernetes対応 K2HDKC DBaaS
OpenStack版と同様に、KubernetesクラスターにK2HDKCクラスターの構築・破棄・スケールができます。
上記の3種類のDBaaSは、以下の簡単な図で示すことができます。
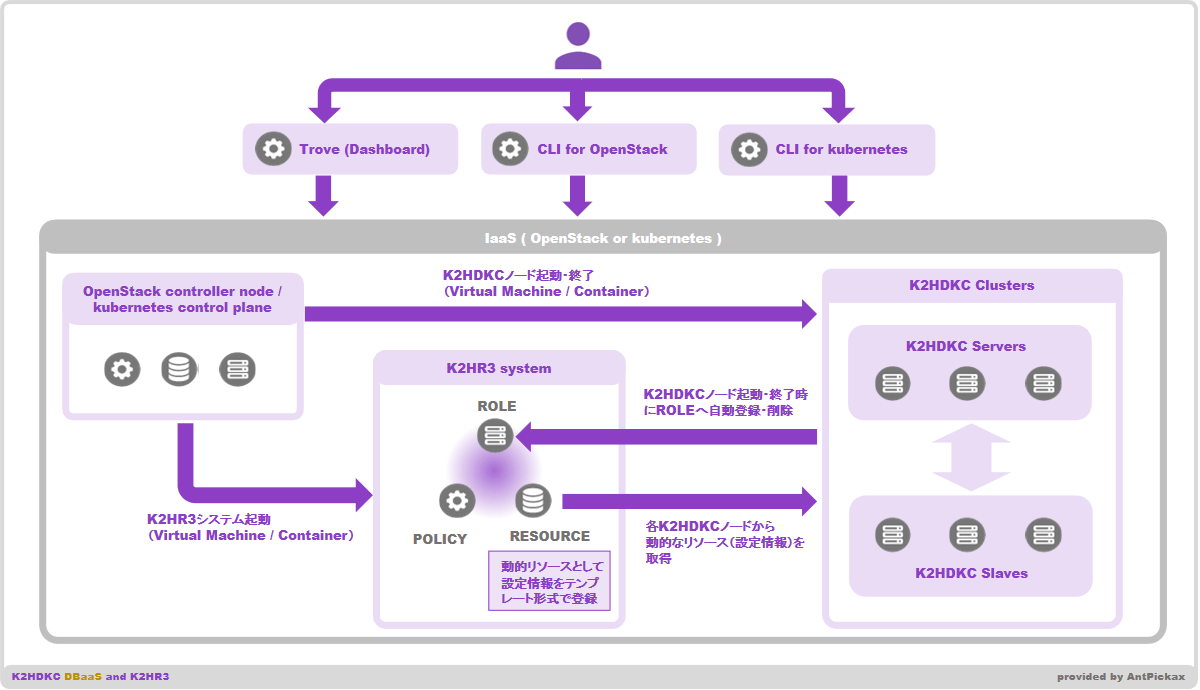
K2HDKCクラスターを構築、破棄、スケール(イン/アウト)する際、設定変更などの複雑な操作は不要で、コマンド(Dashboard、CLI)を実行するだけです。
K2HDKCは、自動でデータマージ(他ノードへの移行)できる機能を有しており、その機能を使いスケールイン・アウトを提供します。
動的な設定情報(コンフィグレーション)
K2HDKC のサーバーノード、スレーブノードの通信には、CHMPXが使われます。
CHMPXは、常時接続のSocket通信を使います。
このため、K2HDKCクラスターを構築するとき、K2HDKCの各ノードのIPアドレスとポート番号を知っておく必要があります。
K2HDKCおよびCHMPXを使ったDBaaSとして機能するためには、動的なノードの増減に対応しなければなりません。
また、増減したノード情報から動的な設定情報(コンフィグレーション)を作り、読み込む必要があります。
上述した3つのK2HDKC DBaaSは、K2HR3を使うことで、ノード増減への対応、設定情報(コンフィグレーション)の動的な生成と更新を可能にします。
つまり、K2HR3を利用することで、K2HDKC DBaaSが実現できます。
K2HR3 の役割
K2HDKC DBaaSは、K2HDKCクラスターの各ノードの情報を集約・管理するため、K2HR3を使います。
前述した3種類のK2HDKC DBaaSは、K2HR3システムをOpenStackが提供するVirtual Machine内、またはKubernetesクラスターが提供するPod(Container)内に構築し、これを使うように構成します。
各IaaS専用のK2HR3システムの構築は、それぞれのツールを使って、簡単に構築できます。
また、既にK2HR3システムが存在する場合、既存のK2HR3システムを使うこともできます。
この場合、既存のK2HR3システムで、複数のK2HDKCクラスターを管理することになります。
K2HR3システムは、K2HDKCクラスターを構成するノードをロールへ自動的に登録・削除します。
各ノードは、このロールに登録されたノードの情報を使い、K2HDKCクラスター全体の設定情報(コンフィグレーション)をリソースとして取り出せます。
そして、各ノードはCHMPXやK2HDKCなどのプロセス起動に必要とされる設定情報(コンフィグレーション)として、このリソースを使います。
K2HR3のリソースへのアクセスは、ロール(に登録されたノード・ホスト)により制御できます。
K2HDKC DBaaSでは、クラスターを構成する各ノードがロールに自動登録されるため、各ノードはK2HR3のリソースに対してトークンなどを必要とせず、アクセスできます。
これにより、各ノードからのリソース取得の処理はシンプルなプログラムで実装できます。
K2HDKCクラスターの設定情報(コンフィグレーション)は、テンプレート記述を使ってK2HR3リソースに登録します。
テンプレート記述を使うことで、各ノードはロールに登録されたノード情報(動的に変化する)を展開した設定情報(コンフィグレーション)を取得できます。
K2HDKC DBaaSは、K2HR3システムを使った一例です。
K2HR3システムは、RBAC(Role Based Access Control)の一つとして、任意のリソース(データ)をロール(に登録されたホスト)から取得することに利用できます。
動的なデータ、例えばロールに依存したデータなどを取り扱いたい場合などに利用できます。
詳しくはこちらを参照してください。
環境への非依存と対応
K2HR3システムは、IaaS環境(Bare metal、Virtual Machine、Container)に依存せず、どこにでも構築できます。
これにより、K2HDKC DBaaSもIaaS環境に応じたK2HR3システムを構築・利用することで、IaaS環境に非依存で構築できました。
つまり、K2HDKC DBaaS と K2HR3 共にIaaS環境に非依存で構築・利用ができます。
今後とも AntPickax の製品は、環境への依存を小さく、動作条件を緩和できるようにしていきたいと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 中谷
- Technial Yahoo



