こんにちは、ヤフーでエンジニアをしている玉城です。
以前、iOS版Yahoo!知恵袋アプリへエッジAIを導入した事例の紹介をしましたが、今回はAndroid版への導入事例をご紹介します。
ここでいうエッジAIとは、スマートフォンアプリにバンドルまたはダウンロードなどをした学習モデルを実行することで、サーバーサイドではなくモバイルデバイス上で推論結果を得ることを指しています。学習モデルの詳しい内容ではなく、用意した学習モデルをAndroidエンジニアがアプリに組み込むという視点で書いております。この記事を通して、導入する上で実施したこと、注意した点、工夫した点などをお伝えすることで導入を検討している方の何かのお役に立てればと思います。
エッジAIを利用して、不適切な質問や回答を投稿前にユーザーに伝える
Yahoo!知恵袋では、日々さまざまな内容の質問やそれに対する回答が投稿されています。これらのほとんどは、適切にやりとりされた問題ない内容のものなのですが、中には他のユーザーが不快に感じるような内容のものもあったりします。
そこで、投稿された内容が適切な内容かどうかを機械学習を用いてサーバーサイドで判定し、他者が不快と感じる内容を含むなど、不適切と判定された投稿はユーザーの目に付きにくいようにするなどの対策ができるようになっています。
この判定をモバイルデバイス上で行うことで、投稿前にリアルタイムでユーザーに知らせるという取り組みを行いました。
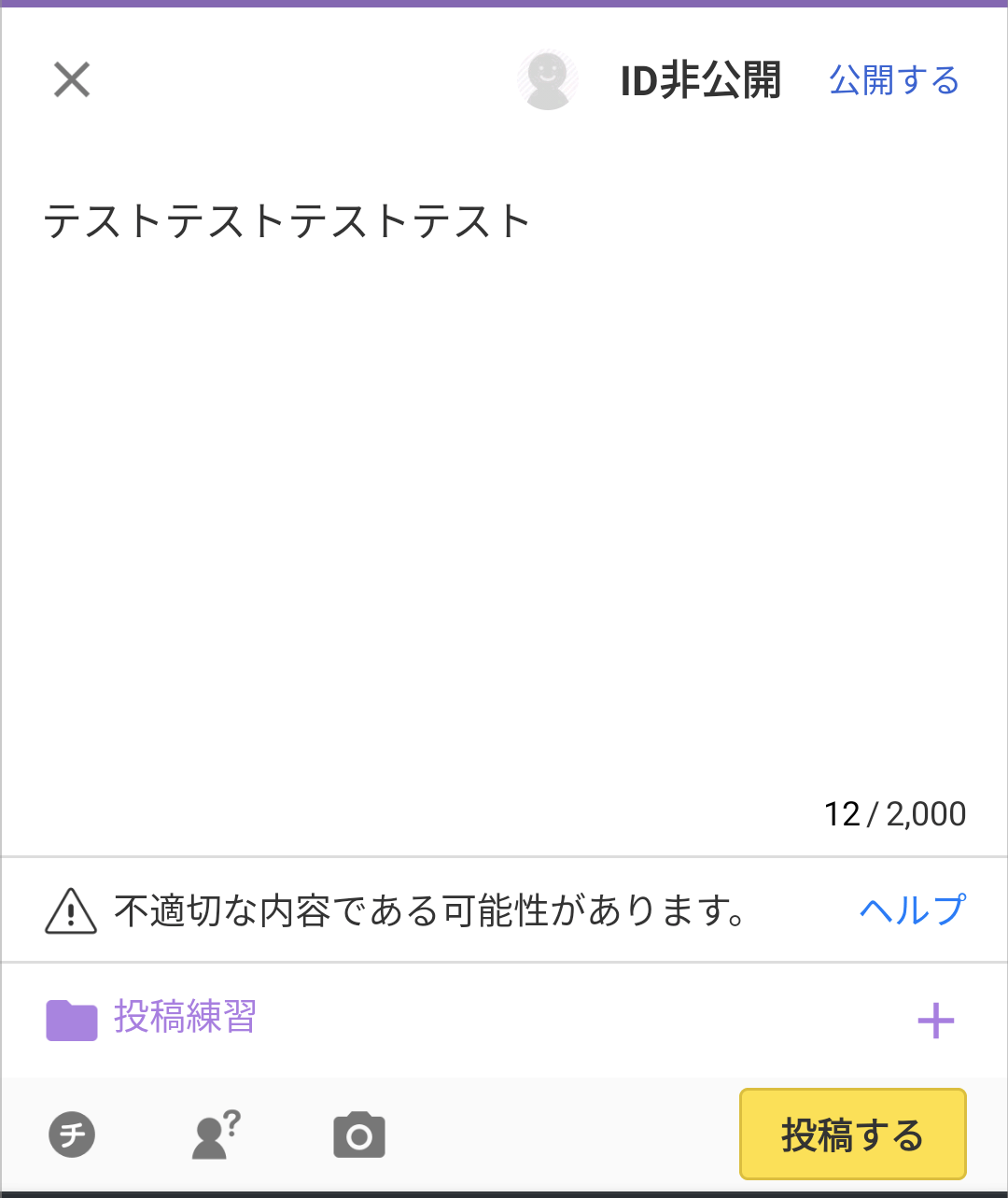
入力中の内容が不適切な可能性がある場合、このような警告文を表示してユーザーに気付いてもらえるようにすることで、警告文を表示した後に投稿をとりやめるなどのアクションをとってもらうことができ、不適切な内容の投稿を一定数減らせました。
これには、以下のようなポジティブな効果が期待できます。
- 悪意なく投稿しようとしたユーザーにとっては、不適切判定により他のユーザーに見てもらい辛くなるということが減る
- 悪意のあるユーザーに対しては警告となり、不快な思いをするユーザーが減る
なぜエッジAIを導入するのか
Yahoo!知恵袋で導入した目的は前述の通りですが、他にもエッジAIを導入することで享受できるメリットがあります。
- パフォーマンスの向上
- 通信量の削減
- セキュリティリスクの軽減
- オフラインでの実行
スマートフォンなどのモバイルデバイス上で推論を実行することにより、サーバーへの入力データの送信と推論結果の受信を行う必要がなくなるため、リアルタイムに近いパフォーマンスで推論結果を得られます。
また、通信する必要がないということは通信コスト削減や、セキュリティリスクの軽減につながりますし、通信環境のない状況でも推論の実行が可能です。
TensorFlow Liteとは
Yahoo!知恵袋では、TensorFlow Liteを使ってエッジAIの導入を行いました。
TensorFlow Lite(外部サイト)
TensorFlow LiteはGoogleが提供する、モバイルデバイスでTensorFlowモデルを実行できるようにするツールセットです。モバイルデバイス上でも利用しやすいように、低レイテンシでバイナリサイズを抑えつつ、機械学習の推論を行えるようになっています。
サーバーサイドで利用しているモデルがTensorFlowであったことと、Android向けの環境が用意されていることが選定した理由です。
TensorFlow Liteの実装ではモデルごとに決まった入出力の次元数を指定する必要がある
実装時に苦労した点としては、Tensorの形状を把握するところです。
推論の実行時には入出力パラメータの各次元のサイズを指定して推論を実行する必要があります。
次元のサイズがわかっている場合はその通りに指定すれば良いですが、そうでない場合は以下の手順でTensorFlow Liteモデルから情報を取得できます。
- TensorFlow Lite形式のモデルからInterpreterを生成する
- 生成したInterPreterから入力用Tensorと出力用Tensorを取得する
- 取得した入出力TensorそれぞれのShapeを取得する
TensorFlowではトレーニング済みのモデルがTensorFlow Hubで提供されています。
これらのモデルを利用する際に、Tensorの形状がわからないといった場合も上記の方法で調べられます。
基本的な実装方法については下記に記載されているので、ご確認ください。
TensorFlow Lite - Androidクイックスタート(外部サイト)
実行速度とアプリサイズの増加に注意
TensorFlow Liteを使えば、学習モデルのバイナリサイズは小さく抑えることができ、実行速度も高速です。
とはいえ、Androidデバイスのスペックはさまざまです。
導入後、実行速度やアプリサイズが許容範囲かどうかを確認しておいた方が良いでしょう。
Yahoo!知恵袋で使用するモデルで推論にかかる時間は、私たちが検証した特定の条件の範囲では十数ミリ秒程度でした。デバイスの処理能力などで前後する可能性があるので、メインスレッドをブロックしないように、推論の実行はCoroutinesを利用して非同期で処理するようにしています。
連続して推論を実行する必要がある場合は、古い情報をUIにフィードバックしてしまわないように推論結果を受け取る順序が入れ替わらないような工夫が必要です。
今回は非同期で実行中のスレッド処理をキャンセルしてから新たな推論処理を実行するようにし、実行中のスレッドが必ず1つになるようにしました。
ファイルサイズについては約10メガバイトとなりました。今回はアプリにバンドルする形としましたが、今後モデルの改善に伴うサイズの増加で許容範囲を超えた場合は、アプリにバンドルせずに別途ダウンロードするといったような仕組みを検討する必要があります。
ダウンロードの仕組みは自作もできると思いますが、Firebase MLでモデルをホストする仕組みが提供されていますので、そちらの利用を検討するのも良いかと思います。アプリの初期ダウンロードサイズを削減するとともに、アプリのリリースなしで常に最新のモデルをデプロイできるというメリットもあります。
Firebase ML(外部サイト)
TensorFlow Lite形式に変換したモデルの評価を実施しよう
TensorFlow Liteガイド - 開発ワークフロー(外部サイト)
精度上の影響を最小限に抑えつつ、モデルのサイズを低減させて効率を改善します。
公式ガイドにはTensorFlow モデルからTensorFlow Lite モデルへ変換しても精度への影響は非常に少ないと記載されています。実際、私たちが検証した範囲でもほとんど差は見られませんでした。
とはいえ、どの程度の影響があるのか、それが求めている品質に達するのかどうかを評価しておくべきです。
Yahoo!知恵袋で作成したモデルは、インプットした内容が不適切な内容である確率を推論結果としてアウトプットします。アウトプットが確率なので、何%以上であれば不適切なのかという閾値を決定する必要があります。TensorFlowモデルと全く同じ推論結果が得られれば同じ閾値を使うという選択肢も取れますが、そうでない可能性もあるので、確認しておく必要があるという訳です。
以下のようにして閾値を決定しました。
- インプットとして不適切な内容、そうでない内容のサンプル文を複数用意
- 作成したモデルに用意したサンプル文をインプットして推論
- 各サンプル文の結果を元に閾値を決める
おわりに
エッジAIの導入というと難しい印象を持っていましたが、導入自体は機械学習への深い知識がなくてもスムーズに行えたと感じました。
今回エッジAIを導入したことで、Yahoo!知恵袋に投稿される内容の品質を向上させられたと思いますので、引き続きモデルのアップデートなどを行い改善していきたいと思います。
最後までご覧いただきありがとうございました。
※今回ご紹介した内容は、私一人の知見ではなく、チームみんなで調査したりアイデアを出したりしたものです。一緒に対応してくださった皆様、ありがとうございます。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 玉城 良憲
- エンジニア
- Yahoo!カレンダーのAndroid版アプリを開発してます。他にも全社横断でAndoridアプリへの新技術の導入などを行っています。



