こんにちは。先端技術の調査報告や深層学習まわりのエンジニアリングを担当している、テクノロジーインテリジェンス室の清水です。
Yahoo!ニュースでは、「記事との関連性の低いコメント」や「過度な批判や誹謗中傷、不快な内容を含むコメント」を表示させなくする仕組みを導入しています。今回の記事では、Yahoo!ニュースの不適切コメント対策のために深層学習ベースの大規模モデルを導入した際、どのように事前学習を行い、高性能な判定モデルの実現に繋げたか、概要をご紹介します。
不適切コメント対策とは
Yahoo!ニュースのコメント欄では日々、数十万件の投稿が寄せられており、その大半は問題がないものですが、中には残念ながら「記事との関連性の低いコメント」「過度な批判や誹謗中傷、不快な内容を含むコメント」など不適切なものがあります。それらはポリシー違反で非表示としますが、対応のため専門家チームによる24時間・365日体制でのパトロールが行われています。また、人手で対応するだけでなく、数年前から(SVMやlogistic regressionに代表されるような)従来型の機械学習による判定モデルが対応ワークフローの中で援用されてきました。
ただ、従来のモデルでは
- 判定精度が十分でなく「実際には問題のないコメントの巻き込み削除」を問題ないレベルまで減らしたとき、検出数がかなり低下してしまう
- コメント単体で「過度な批判や誹謗中傷、不快な内容」について判定する機能は実現できていたが、「記事との関連性」の判定については実現可能性が低く、手付かず
といった課題があり、これらを、BERT・Transformerを始めとする飛ぶ鳥を落とす勢いの深層学習技術でなんとかできないか、ということで開発プロジェクトがスタートしました。
実装とモデル
もともとヤフー社内では、深層学習ベースの大規模自然言語処理モデルの転移学習(事前学習 → fine-tuning)をスムーズに行えるよう、TensorFlow上で以下のような機能をサポートしたframework-on-frameworkを開発・利用しており、今回についてもそれを利用して作業を進めています。
- テキストデータ前処理・データセット生成
- TransformerやLSTM等のモデル自体のアルゴリズム
- 事前学習モデル・実際の判定モデル それぞれの性能評価
- 事前学習済みモデルを用いて次のステップに進む際の、パラメータの引き継ぎやフィルタアウト処理
- synchronous modeあるいはasynchronous modeでの学習の並列化
TransformerやLSTMの実装については最近であればフレームワーク側でサポートされておりそれを使うのが一般的かもしれませんが、このあたりのコア部分についても独自に工夫したり、最新の知見をいち早く取り込んだりできるよう、あえて独自の実装を選択肢として残してあります。
モデルアーキテクチャとしては、SQuADやGLUEなどの総合ベンチマークの結果を見ても今はまさにself-attention全盛、Transformer全盛ですので、Transformerのencoderアーキテクチャを採用することとして。規模的には、推論時のスループットやレイテンシの観点でCPU上でもぎりぎり問題なく回せる程度の、数千万パラメータ規模としました。
また、自然言語処理における日本語テキストの前処理といえば形態素で区切るのが最も一般的ですし、最近であればsentencepieceなどによるサブワード分割も使われるようになってきていますが、今回扱う対象の文章の中にはかなりくだけた口語的なものが多く、文字単位で処理する形にしています。
事前学習
Transformerアーキテクチャなモデルの事前学習といえば、BERTの論文にあるように「文の穴埋め(masked language model、MLM)」「与えられた2文が実際に前後でつながったものなのか、無関係なものか判断(next sentence prediction、NSP)」のマルチタスクで行うのが一般的です。後者はその後の研究で「あまり効果がないのでは」という話も出てきており、文の穴埋めのみで事前学習を済ませるケースも増えてはきましたが。一方、文の穴埋めのみでは「与えられた文全体を理解して、一つのベクトル表現に落とし込む」という、最終的にfine-tuning時に計算過程として必要とされる要素が直接的には含まれておらず、このあたりが高い性能を得る上でのネックになる可能性があります。
そこを手当てするため、今回は「文の穴埋め」と「与えられた2つの文の表現のペアが、実際にペアになるものか無関係なものかどうか、マッチングして判定(deep structured semantic model、DSSM)」の2つのタスクで事前学習を行いました。
DSSMでは以下のように、テキストの入力を受け付けてベクトル表現を出力するようなencoderを2つ組み合わせて使います。本体のパイプラインのアーキテクチャは全結合層やCNN、LSTM、Transformerなどいろいろバリエーションはありえますが、今回はTransformerです。
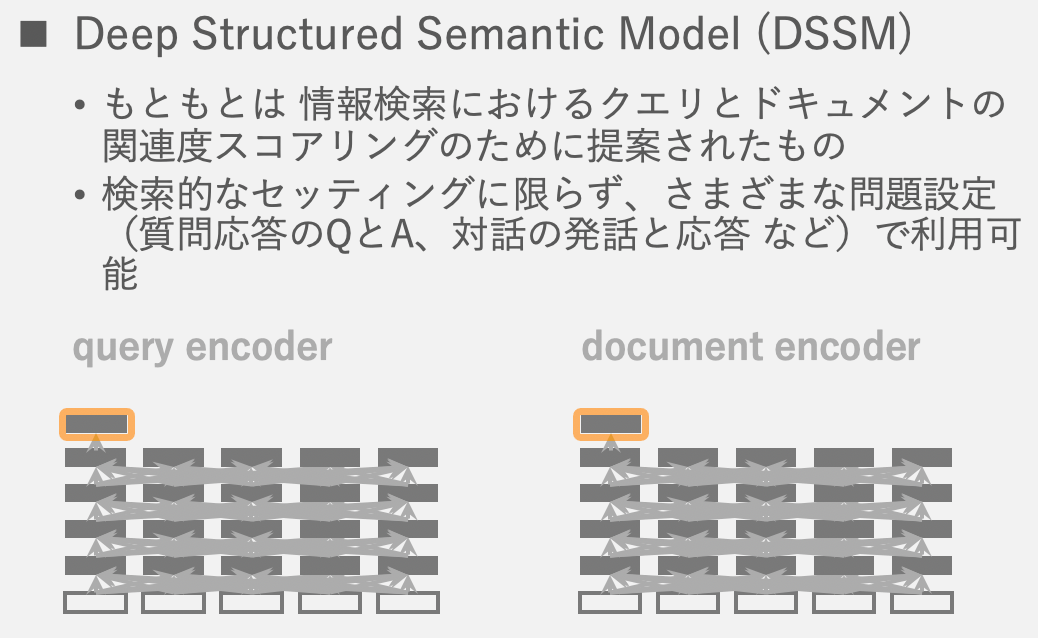
そして、入力されたテキストのペアが、実際に関連するものであればそれぞれのencoderが出力した表現が近くに来るように、関連しないものであれば遠くに離れるように学習していきます。下図は対話的な文のペアを学習するような例になっており、「おはよう」に対して「おやすみ」は実際に関連するものなので出力された表現zが近くに来るように、類似度Rが大きくなるようにフィードバックがかかります。
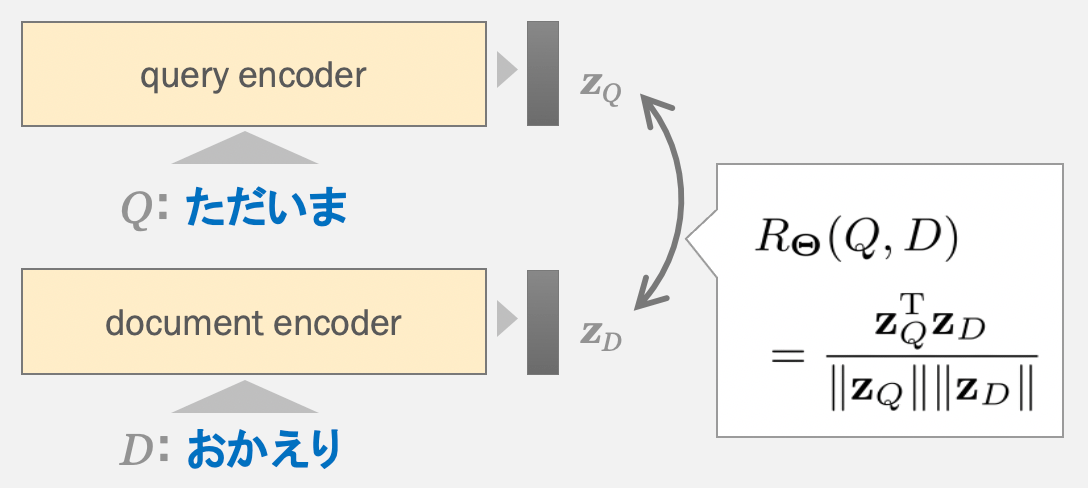
これらの図からも見て取れるとおり、DSSMの事前学習モデルでは、与えられたテキストを代表するような表現を必ず作ってから次の工程に進む形になっていて、学習が進むにつれてその表現の質も良くなっていきます。得られたモデルが分類モデルへのfine-tuningに適しているのはもちろんのこと、テキストの分散表現をベースとしたさまざまな用途に使えるというメリットがあります。
ちなみに、ここで用いるような数千万パラメータの大規模モデルであれば、かなり大量のテキストを与えて学習したとしても簡単にオーバフィットしてしまいます。これを緩和するため、ニュースコメントのテキストだけでなく、Yahoo!知恵袋のテキストも援用して事前学習を行いました。
第一段階として、まずは数千万ペアのYahoo!知恵袋の質問 - ベストアンサーのペアをMLMとDSSMのマルチタスクで学習します。この学習の中では「与えられた質問に対する、正しい回答を見分ける」ことをやらせるわけですが、このタスクがこなせるようになった時点で「日本語を読める能力の素地」が得られたとみなせるでしょう。
そしてさらに、第一段階でできたモデルを引き継いで、第二段階の、ニュース記事およびそれについてのコメント 千数百万件を用いた学習に移ります。このステップでは学習済みのモデルを2つに分岐させるのですが、一つは「記事 - コメント」のペアデータで学習させたもの、もう一つが「コメント - 返信」のペアデータで学習させたものです。方式的には変わらず、MLMとDSSMのマルチタスクで学習させます。記事とコメント、コメントと返信、というYahoo!ニュースのコメントデータにおける、このような2種類の関連性を学習させることが最終的に行いたい判定モデルを得ることにつながるというわけです。
事前学習は非常に大量のデータを扱う重たい処理ですので、2017年に構築したスーパーコンピュータkukaiを部分的に利用する形で並列化して進めました。
fine-tuning
最後の第三段階はfine-tuningです。最終的に検出したいものとして「記事との関連性の低いコメント」「過度な批判や誹謗中傷、不快な内容を含むコメント」2種類がありましたが、事前学習済みモデル2つが、それぞれどのように適用されるか見ていきましょう。
まず、「記事との関連性の低いコメント」の判定は、基本的に記事とコメントのペアが与えられて、それについてモデルがOK/NGを出力する形です。この判定向けに、記事とコメントのペアで事前学習したベースモデルを、正解データを与えつつfine-tuningします。DSSMで得られた記事のencoder、コメントのencoder、それぞれから得られた表現を連結し、それをもとに判定を行うようなアーキテクチャとしています。
そして、「過度な批判や誹謗中傷、不快な内容を含むコメント」については、コメントの投稿 単体での判定になりますが、ここではコメントと返信のペアで学習したベースモデルを、正解データを与えつつfine-tuningします。コメントの内容に応じて返信コメントが付いていく中で、例えば不快なコメントに対しては(その書き方を諌めるような返信や、さらに反発して相手を不快にさせる返信など)その内容なりの返信コメントが付きますが、そのようなパターンを事前学習の中で把握しておくことで、最終的な「不快な内容を含むコメント」の判定に資することができるでしょう。
考え方としては、ACL 2018の採択論文 Pretraining Sentiment Classifiers with Unlabeled Dialog Data (Toru Shimizu, Hayato Kobayashi, Nobuyuki Shimizu)の提案手法と相似形です。この論文は「tweetの対話データにおいて『positiveなつぶやきにはpositiveなりの、negativeなつぶやきにはnegativeなりの返信が付いている』というような、つぶやきと返信の関連を事前学習しておくと、これが感情分析を陰に学習しておくことになり、実際の感情分析タスクにfine-tuningしたときに高い性能を得ることができる」というものでしたが、tweetをコメントに、感情分析タスクを不快判定タスクに置き換えるとちょうど同じ話になります。
深層学習モデル導入の効果と、初期リリース後の改善点
導入後の効果としては、2020年3月にリリースした「過度な批判や誹謗中傷、不快な内容を含むコメント」判定モデルでは既存のシステムより誤判定率を増やすことなく、検出数を2.2倍に高めることができています。それに先立って2019年12月にリリースした「記事との関連性の低いコメント」判定モデルでは、人手でだけ判定していたときに比べて、問題のあるコメントに対応するまでのリードタイムを飛躍的に短くすることができました。
関連性の判定モデルは初期のリリースではBERTをベースにしており、next sentence prediction的な仕掛けで「記事とコメント、両方の情報をつなげて入力し、判定結果を得る」方式でしたが、この形は運用が進む中で「学習時に見たことがない話題の記事についての汎化性能が思った以上に低い」ということが分かってきました。記事側の情報を細かく見すぎるようなオーバーフィットが起こっていたわけですが、BERTのままだと記事とコメントと常に同列に扱う形になってしまい、記事側にだけ必要な対策を施すことができません。結果、Transformerベースのアーキテクチャはそのままとしつつ、BERTではなく別の形にして改善しています。
今後の展開
今後の展開としては、技術面においては、同様の技術をYahoo!ニュースのコメント機能だけではなく、ヤフーのサービス上で扱うUGC的なコンテンツ全般に適用可能にするための取り組みを進めています。また、Yahoo!ニュースのコメント機能においては、不適切なコメントへの対応という「守り」の側面だけではなく、例えば、より多くの人に読んでほしい価値あるコメントを発見するなど、投稿されたコメントを活用し、コメント機能自体をより便利なものとできるよう開発を進めていければと考えています。
関連リンク
- Yahoo!ニュース コメントの健全化に向けた取り組み(Yahoo! JAPAN Corporate Blog)
- Yahoo!ニュースの「不適切コメント対策」最前線――自然言語処理研究者に聞く、スパコンによる機械学習導入後の変化とは?(newsHACK)
- 最先端の自然言語処理モデルとスパコン「kukai」を活用したコメント対策、および並び順名称の変更について(newsHACK)
- Yahoo!ニュース、最先端の「深層学習を用いた自然言語処理による判定モデル(AI)」と独自スパコン「kukai」を活用し、コメント対策を強化(プレスリリース)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 清水 徹
- CTO技術戦略本部 機械学習エンジニア
- AIまわりの先端技術調査とあわせて、実サービス向けのモデル学習も手掛けています。



