こんにちは、ヤフーで不正対策システムの開発を担当している塚原です。
ヤフオク!やYahoo!ショッピングといったヤフーのコマースサービスにおける不正決済検知の仕組みについて、システムへの機械学習の適用方法を中心にご紹介します。
テーマはずばり、「ルールと機械学習の融合」です。
今回ご紹介する事例はあくまで不正決済検知に関するものですが、すでに何かしらの判定ロジックをシステムで組んでいて、そこに機械学習を適用させるという点においては汎用的なテーマです。ですので、不正対策やコマース領域以外のサービスに関わる方にもご参考にしていただければ幸いです。
不正決済とは
そもそも不正決済とは何か? ということですが、クレジットカードや銀行口座残高、保有ポイントなどが他人により勝手に使用される被害を指します。
代表的な手口としては、盗用クレジットカードによる決済、のっとりアカウントによる決済などがあげられます。他にも各サービスにおける利用規約違反なども対象です。
こうした不正決済は手口がさまざまで、犯人や手口の特徴、傾向が頻繁に変化していきます。
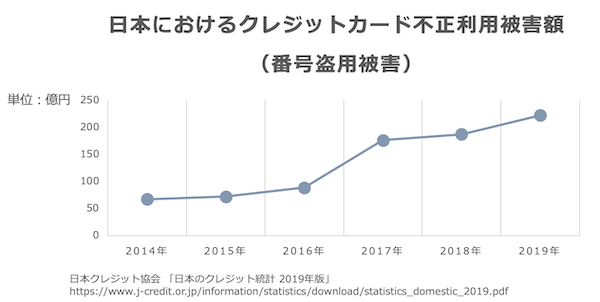
以下の図は日本クレジット協会が公表している、国内のクレジットカード不正利用被害額のうち、おもにオンライン決済における被害を示す「番号盗用被害」の推移です。
ご覧いただくとわかるとおり、不正決済の被害額は年々増加傾向にあり、こうした不正決済に対する対策は必須となっている状況です。
検知システムの概要
それでは、検知システムの概要について見ていきます。
ユーザーが決済を行ったタイミングで、リアルタイムにその決済情報をチェックし不正かどうかの判定を行います。
判定はシステムによる判定と人による判定を組み合わせた判定フローになっています。

検知システムは外部ソリューションを使わずに独自に開発を行うことで以下のメリットを得られます。
- 外部データ送信によるセキュリティリスクの回避
- 低コスト(多くの外部ソリューションではトランザクション単位での従量課金体系になっている)
- 仕様変更に柔軟に対応可能
- ヤフーの各サービスで蓄積されたデータの横断的活用
システム概要
こちらがシステムの概要図です。
ルール登録→判定→結果分析→ルール修正 というフィードバックルールが構築され、ルールが改善されていく仕組みとなっています。
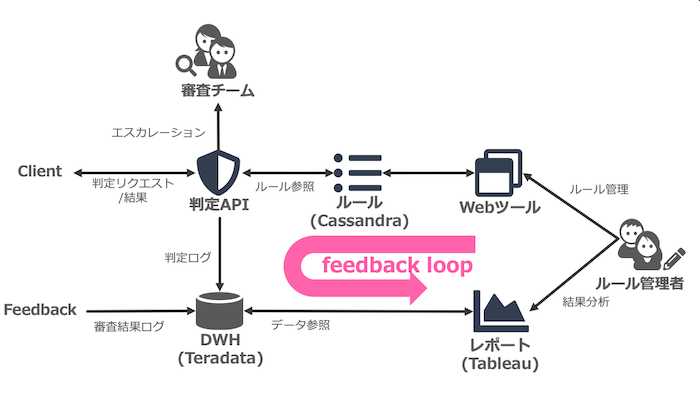
- ルール管理者が専用Webツールにてルールを登録する
- ルールはデータベースに格納され、判定APIは判定リクエストが来たタイミングでデータベースを参照し、判定結果を返す
- 完全に判定しきれないものは審査チームにエスカレーションする
- 判定結果や審査結果のログは最終的にデータウェアハウスに蓄積される
- データをレポート化し、それをもとにルールを改善する
ルール構成
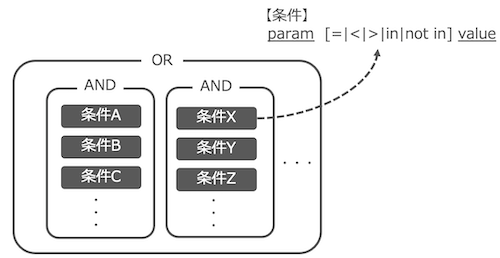
判定に使うルールについて補足します。
ルールは基本的に条件としきい値で構成され、複数の条件をAND/OR条件で組み合わせてひとつのルールを作ります。例えば、あるパラメータ値が、ある値と等しい、ある値より大きい/小さい、含む/含まないといった感じです。
使用するパラメータは判定APIのリクエストパラメータとして送られてきたものや、API側で独自に保持しているデータを使います。
ルール VS 機械学習
ここまでルールベースの判定システムについてお話ししてきましたが、いったんここで「ルールと機械学習の違い」という話題に移りたいと思います。
ルールベース判定の特徴
ルールベースの判定の特徴は、判定理由が明確であること、即時修正が可能であること、細かい調整が可能であること、という点があげられます。例えば「何かの金額が1万円以上だったら」というルールを作り、金額を9900円に下げたり、11000円にあげたり自由に調節が可能です。
一方、ルールは人手で作ることになるので、ルール作成に手間がかかります。また不正傾向の変化に追従してルールを常に更新しつづけていくことは難しいです。
機械学習モデルの特徴
では機械学習はどうでしょうか? こちらは精度の高い判定を行えることや、モデルを自動的に更新して傾向の変化に追従していくことが可能です。
一方デメリットとしては、ルールの調整とは違い、モデルの再学習が必要となるため即時修正が行えません。また、ディープラーニングのような複雑なモデルを使うとモデルの説明性を担保することが難しくなってしまいます。
それとシステム面でも、機械学習のパイプラインを組み込むことでシステムが複雑化してしまいます。
| GOOD | BAD | |
|---|---|---|
| ルールベース判定 | ・判定理由が明確である ・即時修正が可能である ・細かい調整が可能である |
・ルール作成に手間がかかる ・ルールのメンテナンスが難しい |
| 機械学習モデル | ・高い判定精度 ・自動的なモデル更新 |
・即時修正が行えない ・モデルの説明性の担保が難しい ・システムの複雑化 |
不正判定特有の課題
また、ルールと機械学習の適用を比較検討する上で不正判定特有の課題というものも考慮する必要があります。
1つ目の課題は、偽陽性判定(False Positive)を抑える必要があるということです。通常の決済を誤って不正と判断することで、ユーザーに迷惑をかけてしまうことは極力避けなければなりません。
2つ目は、高い説明性が求められるということです。なぜ不正と判断したのか、ある程度理解し自分たちが今どういう特徴の決済を不正あるいは正常と判断しているのかを把握しておく必要があります。
3つ目は、すべての判定を機械学習モデルに任せることは難しく、ビジネスのドメインルールに基づいたルールベースの判定が必要不可欠であるということです。利用規約違反や過去の不正履歴との照合などがそうしたルールに該当します。
ルールと機械学習を融合させる!
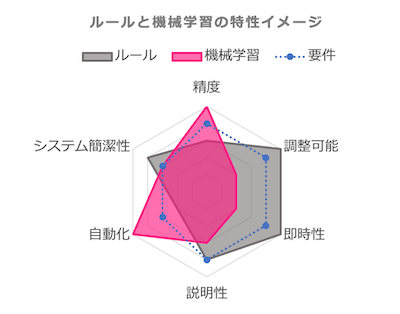
ここまで見てきたルールと機械学習の特性をチャートにしてみました(定性的な数値となってしまいますが、あくまでここはイメージとして捉えてください)。
グレーがルールベース、ピンクが機械学習、青が求められる要件レベルを表しています。
ルールでは、「調整可能」や「即時性」、「説明性」の項目では要件を満たすことができる一方、「精度」や「自動化」の点で要件を満たすことができません。この2点はまさに機械学習が得意とするところなので、機械学習を適用することで既存のルールベースシステムの弱点を補うことが可能です。
機械学習の適用方法その1:機械学習の判定スコアをルールに組み込む
方法の1つ目は、機械学習モデルの判定スコアをルールの1条件として組み込むことです。流れとしてはこのようになります。
- 判定モデルを作成
- モデルの推論APIを用意
- モデルのスコアを条件にしたルールを登録
- スコア取得&ルール参照
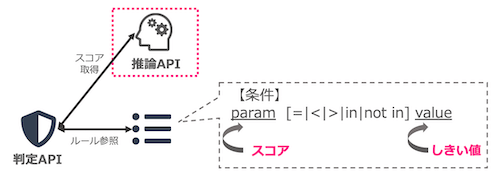
まず過去の不正データをもとに判定モデルを作成し、そのモデルをサービングする推論APIを用意します。
ルールの方では、あらかじめ「モデルのスコアがあるしきい値以上だったら」という条件でルールを作成しておきます。
判定APIは判定時に推論APIをたたいてスコアを取得した上で、ルールを参照します。
実現できること
この方法では、モデルの出力をルールでラッピングすることで、既存のルールベースの体系の中でモデルの結果を扱うことができます。
これによりスコアのしきい値を自由に調整でき、スコアと他の条件を組み合わせたルールも作成可能です。
また、即時性や調整が可能であるという、ルールベースのメリットをモデルのスコアに対しても活かすことができるようになります。
留意点
一点留意点としては、モデルの出力スコアの補正(キャリブレーション)についてです。
不正判定モデルの学習データは一般的に正例/負例が極端に不均衡なため、モデル学習時にはアンダーサンプリング等の手法が取られることが多いです。
そのため、不正の確率値を表すモデルの出力スコアが実際の確率値と乖離してしまう現象が発生します。そのような状態だと、ルールの条件を作成する上で、「80%以上の確率だったら」というような指定が意図通りに行えません。
アンダーサンプリングの場合は、サンプリング率をもとにスコアに補正をかけることである程度実際の確率値に近づける必要があります。
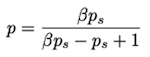
Calibrating Probability with Undersampling for Unbalanced Classification(外部サイト)
- p=補正後の確率
- p_s=不均衡モデルの予測確率
- β=サンプリング率
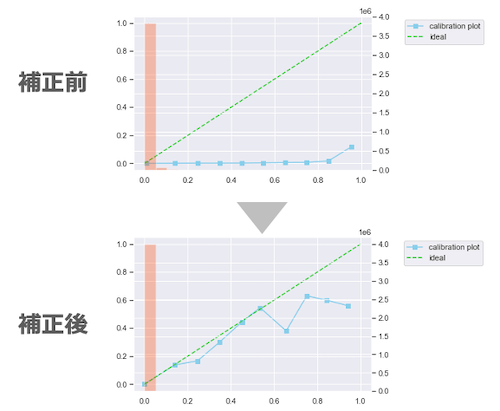
こちらは実際にスコア補正の検証を行った際の結果です。
横軸がスコア、縦軸が実際の確率値となっています。そのため緑の斜めの線がスコアと実際の値が完全に一致している理想の状態を表します。
検証の結果、補正によりスコアが理想値にかなり近づいていることが確認できます。
スコアの補正が必要なケースは、今ご説明したようなアンダーサンプリングを行った場合の他に、Random Forestや SVMのようにモデルの出力値が確率値ではないアルゴリズムのモデルを使用した場合も考えられます。
スコアが非確率値のモデルの場合ですが、こちらは別途変換モデルを使って確率値に変換するような手法が取られます(scikit-learnのライブラリで用意されている、Isotonic calibration および Sigmoid calibrationなど)。
機械学習の適用方法その2:ルール自体を機械学習で自動生成する
次に2つ目の機械学習の適用方法についてご説明します。
それは、「ルール自体を機械学習で自動生成する」というものです。流れはこのようになります。
- 決定木モデル作成
- 適合率の高いノードを選定
- 選定したノードまでの分岐情報を抽出
- ルールに変換&登録する
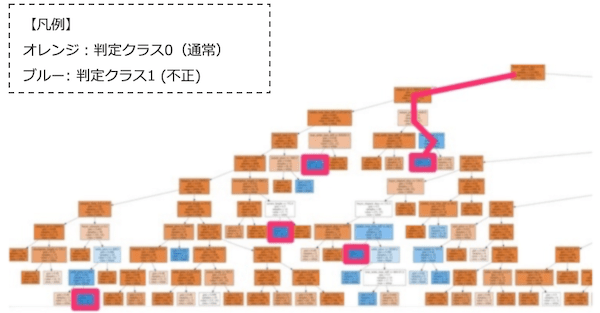
1. 決定木モデル作成
まず、過去の不正データをもとに決定木による分類モデルを作成します。
2. 適合率の高いノードを選定
図のオレンジ色のノードが「通常決済の確率が高いノード」、青のノードが「不正の確率が高いノード」を表しています。 ですので、ピンク枠で囲っている色が青く濃くなっている箇所が特に不正の確率が高いノードに該当します。
3. 選定したノードまでの分岐情報を抽出
そして次に、この青くなっているノードまでの分岐条件を抽出します。ピンクの線がその分岐条件をたどったものになります。
1st: parameter_A > 50000
2nd: parameter_B = 333
3rd: parameter_C < 1
4. ルールに変換&登録する
各分岐条件は「ある値がいくつ以上だったら」という内容なので、そのままルールに置き換えることが可能です。
rule1 = (parameter_A > 50000 & parameter_B = 333 & parameter_C < 1)
出来上がったルールは検証用の過去データにあてて精度を確認し、精度が一定以上のものを採用します。
rule1: precision = 0.2 ← 不採用
rule2: precision = 0.8 ← 採用(threshold = 0.7)
採用されたルールは既存のルールと同様DBに格納され、判定に利用されます。
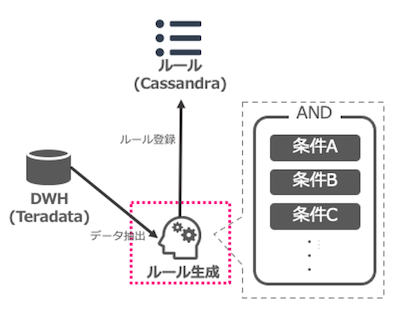
実現できること
決定木自体は以前からある基本的な機械学習のアルゴリズムです。しかしここでのポイントは
- 決定木モデルをそのまま判定モデルとして使うのではなく、適合率の高いノードのみを選定し使う点
- 分岐条件を「ルールに変換して」既存のルールベースシステムに投入している点
にあります。
この方法の特長は、モデルのアウトプットがそのままルールになることです。
そして人手で作るルールとは違い、自動で作成・更新が可能です。
決定木というシンプルなアルゴリズムですが、ツリー全体ではなく部分的に採用することで高い適合率を実現しています。
また、モデリングに必要な計算リソースも非常に少なく済みます。
留意点
この手法での留意点としては、過学習があげられます。
決定木自体がもともと過学習しやすい傾向があるため、その対処としてモデル学習時にtrainデータ/validationデータを切り出す際には、ユーザIDと時系列での分割を実施しています。
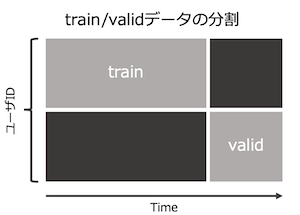
ユーザIDでの分割は、特定ユーザの特徴に依存しないようにするためです。
時系列での分割については、決済データは時系列データではないので本来厳密に期間を区切る必要性はないのですが、ある程度トレンドの変化に左右されない汎用性のあるモデルにするという狙いがあります。
機械学習適用後のシステム概要
では、もともとのルールベースのシステムに機械学習モデルを組み込んだあとのシステム概要図を見てみます。
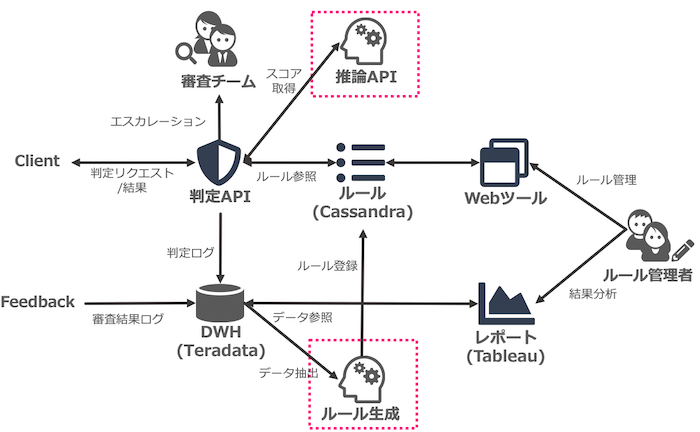
ピンク枠が追加された箇所です。
推論APIによるスコアを取得する箇所、それから決定木により生成したルールを登録している箇所の2点です。
注目していただきたいのは、既存の判定フロー、フィードバックのサイクルには影響を与えずに、機械学習モデルがルールベースシステムに組み込まれている点です。
審査チームやルール管理者の運用フローが変わらないという点が、あらたに機械学習を組み込む際に重要なポイントです。
まとめ
ルールベースのシステムに、
- 「機械学習の判定スコアをルールに組み込む」
- 「ルール自体を機械学習で自動生成する」
という2つの方法で機械学習モデルを適用することで、ルールと機械学習それぞれの特長を生かした検知システムを構築している事例をご紹介しました。
この施策の導入により検知の質、量ともに向上し、対象の各サービスの平均値でルール数は約33%増加、不正防止金額は約10%増加させることができました。
安全に取引ができることでより多くの人がオンラインでの買い物を楽しめるように、これからもシステムの改善、モデルの精度向上に取り組んでいきたいと思います。
最後までご覧いただきありがとうございました。
関連リンク
本記事の内容は、先日開催されたYahoo! JAPAN Tech Conference 2021でも発表しています。よろしければこちらのリンク先のアーカイブもご覧ください。
- ルールと機械学習を融合させた不正決済検知システム(登壇資料)
- ルールと機械学習を融合させた不正決済検知システム(登壇動画)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 塚原 剛
- 機械学習エンジニア
- 不正対策システムの開発を担当。他にデータ分析・機械学習モデルの作成など。



