先日アスクル/一休/PayPay/ヤフー/ZOZOテクノロジーズで共同開催した、企業内ハッカソンイベント「Internal Hack Day」参加者からの寄稿記事を紹介します。
イベントについてはこちらをご覧ください。

こんにちは。ヤフー株式会社の中西です。今回、Internal Hack Dayという社内ハッカソンイベントに参加したので、そのレポートをまとめました。同じヤフー大阪オフィスの同期である中條君と本田君と一緒に、イベントの2日間でどう取り組んだか、何を学んだかについてお話ししたいと思います。
今回開発したもの
まずタイトルにある通り今回私たちが開発したのは「次世代型影武者」です。次世代型影武者ってなんやねんと思われるかもしれないので、開発の経緯から説明していきたいと思います。
背景
事の始まりはHack Dayの案出しでチームメンバーである中條君が言った一言。「リモート会議中おなかが痛くなった時、すぐ離席しますって言いづらいよね」
確かに世の中は新型コロナウィルスの影響でリモートワークが増えています。ヤフーでもリモートワークが続いており、会議中の離席はリモートであってもためらわれるものです。「じゃあ、そんな時に代わりに会議に出席してくれる影武者を作ろう!」そういって開発が決まったのが次世代型バーチャル影武者「ムシャムシャ君」です。
作品説明
「無者」で「影武者」だから「ムシャムシャ君」。名前の通り、会議に人がいない間に出席してくれる影武者です。当然バーチャルなので実体はなく、アプリケーションで表示させたアバターが会議に参加します。
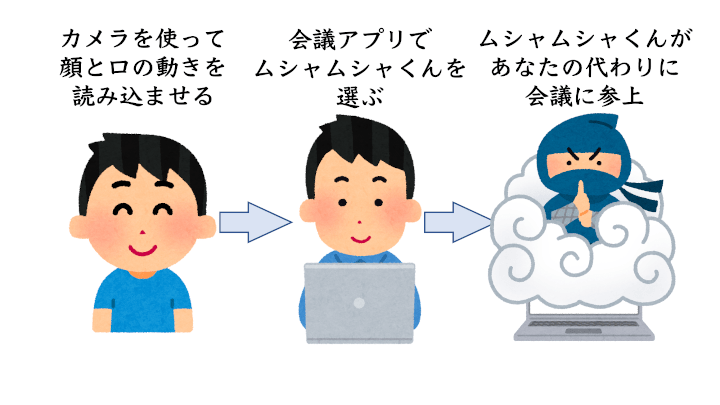
離席する時でもワイヤレスイヤホンを使えば話に参加することはできるので、「声に合わせてアバターがしゃべれば、自分があたかも普通に会議に参加しているように思わせられるのでは?」と思いこのようなシステムを構想しました。近年コンピューターグラフィックスのキャラクターを通してYouTubeの配信をするバーチャルYouTuberというものがはやっていますが、その本人画像を使ったバージョンをイメージすれば分かりやすいかもしれません。
開発の流れ
まず、このシステムに必要な構成要素は
- 会議に参加している動画と顔の位置の認識
- 「あ」「い」「う」「え」「お」の母音の認識
- 認識した音声の口画像を動画に合成
- これら全てを組み合わせたアバターを表示するアプリケーション
の4つと考え、以下のような分担で2日間取り組みました。
画像合成担当:中西
音声認識担当:中條
顔認識&アプリケーション担当:本田
メンバーは月に1回プライベートで登山に行くほどの仲です。今回は山登りで培ったスタミナとチームワークで開発に臨みました。
技術解説
システム構成
システム構成は以下の図です。
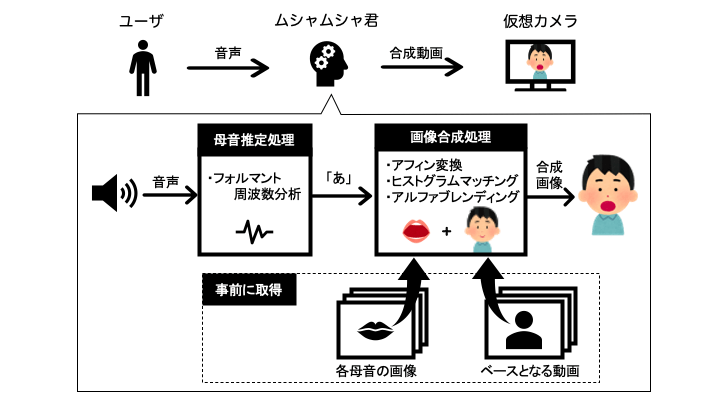
言語はPythonでアプリケーション部分はTkinterを利用しました。ちなみに開発言語にPythonを採用したのは
- 画像認識や音声認識のライブラリが豊富
- 参考になる記事が多い
というのが主な理由です。
処理の流れについて説明します。まず、事前準備としてアバターのベースとなる会議に参加している自分の動画と「あ」「い」「う」「え」「お」の母音をしゃべった時の自分の画像を入力します。ベースの動画は一定間隔のフレームに分割し複数画像として保持します。
アプリケーションを起動したら音声の入力を開始します。音声はリアルタイムで入力され、その特徴量から母音に分類します。
母音を分類した後、事前に取得しておいたベース画像の口の位置に母音に対応する口画像を違和感なく合成しアバターを作成します。口の位置は機械学習ライブラリのDlibの顔ランドマーク検知を用いて自動特定しました。
最後に出来上がったアバターをリモート会議に参加させれば準備完了です!リモート会議システムのカメラをバーチャルカメラに映したムシャムシャくんに切り替えればあとの会議はムシャムシャ君が代わりに参加してくれます。
音声認識
今回音声認識ではフォルマント周波数と呼ばれる値を特徴量として使用しています。音声は声帯が発した空気の振動が声道で共鳴することで発生しますが、フォルマント周波数とはその声道で強く共鳴する周波数のことを意味します。
以下の画像は今回開発するにあたって録った「あ」と「い」の発音の特性を求めた結果です。
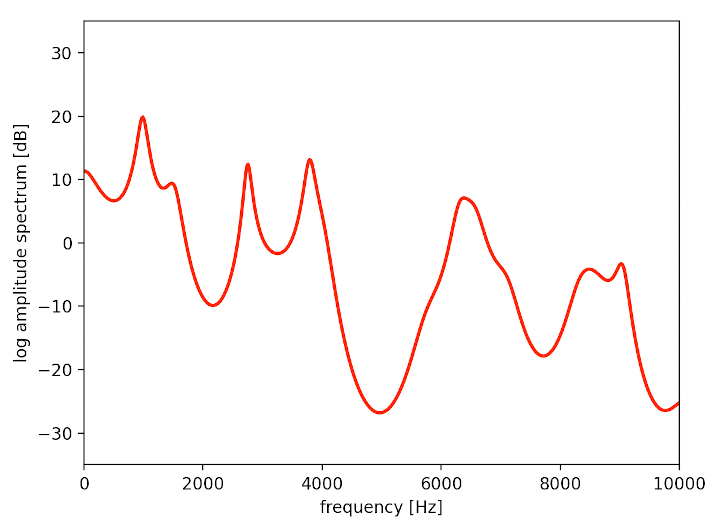
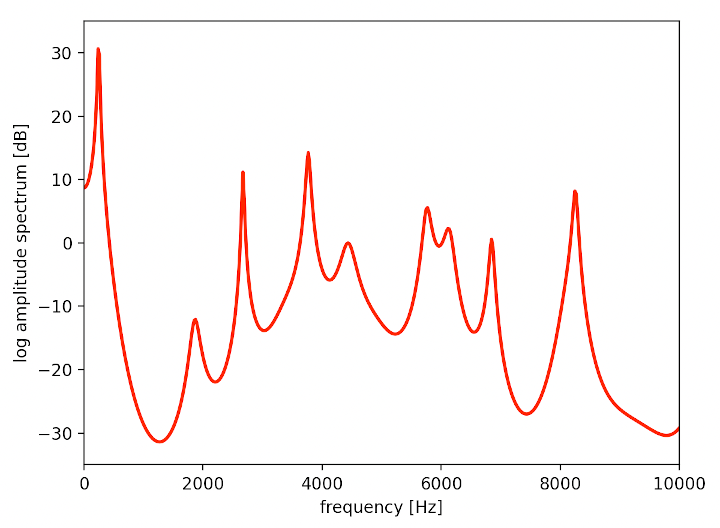
赤い線を周波数(横軸)の低い順から見て、振幅スペクトル(縦軸)が最初に跳ね上がっている値を第一フォルマント、次に跳ね上がっている値を第二フォルマントと呼びます。発声者が異なっていても同じ母音では跳ね上がる位置が近くなるため、母音はこの特徴量を使って分類できます。
システムを開発する上では「あ」「い」「う」「え」「お」に対応するフォルマント周波数のデータが必要だったわけですが、中條君はこれを自分の声で量産してくれました。ムシャムシャ君の音声認識システムは中條君の涙ぐましい努力によって成り立っています。
ただ、ひたすら母音をしゃべってデータを取っている中條君の姿は少しシュールでした。

画像合成
違和感がないように口画像をベース画像に合成するためには
- ベース画像の決められた位置に口画像を変形させて貼り付ける
- 口画像の色合いをベース画像の色合いに寄せる
- 貼り付けた口画像とベース画像の境界を違和感なく溶け込ませる
といった手順が必要です。これらは、アフィン変換、ヒストグラムマッチング、アルファブレンディングと呼ばれる画像処理によってそれぞれ実現しました。画像処理はOpenCVとscikit-imageを用いて開発しました。
以下の図が順番に画像処理を適用していった結果です。右にいくにつれて口画像が違和感なく合成されていることがわかります。

最初はなかなか違和感なく合成できず苦労しましたが、アップデートを繰り返しなんとか納得できる合成結果まで持っていけました。実装途中バグで何度も本田君が不思議な姿になったことには目をつむることにします。

完成したシステム
以上の開発を経てできたムシャムシャ君がこちら。無表情で口を動かす姿は不気味の谷を感じさせますが会議に紛れ込んでもあまり違和感がなさそうです。
会議に参加させてみました。バーチャル背景もしっかり適用されます。
これでいつ如何なる時でも完璧なコンディションの姿で会議に参加できますね!上長から「なんか今日カクカクしてるやん! どないしたん?」と言われたら「うちのマンション、ネット環境良くないんですよ!」とでも答えましょう。
おわりに
今回が初めてのハッカソンということもあり、右も左もわからない中での参加となりましたが、最後にはイメージした通りのシステムを開発することができて一安心でした。しかし、まだまだ技術的な課題もいくつか残っており、
- とにかくプログラムが重い(アプリケーション単体では問題ないがリモート会議システムで使うと途端にパフォーマンスが落ちる)
- 音声認識精度の向上(もっといろいろな人のサンプルデータをとる、より精度の高い分類方法を用いるなど)
- より違和感のない合成(合成ではなくてGANを使って生成するとか)
などなど、もう少し時間があれば…! と思うところも少なくありませんでした。2日という限られた時間でアイデアを形にするためには、エンジニアとして使える技術の引き出しをより多く持っておく必要があるのだと改めて実感しました。Internal Hack Dayはそのような学びや発見が盛りだくさんな、有意義な2日間でした。このイベントは定期的に開催されていますので、機会があればまたチャレンジしてみたいと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 中西 創
- Yahoo!地図エンジニア
- Yahoo!地図のナビゲーションシステムのバックエンドを担当しています。

- 中條 太暉
- サービスプラットフォームエンジニア
- Tech Blogをはじめとしたウェブサイトを動かすための基盤となるシステムの開発・運用をしています。

- 本田 美輝
- サービスプラットフォームエンジニア
- 社内プラットフォームを開発・運用しています。
-



