こんにちは。ヤフー広告 ディスプレイ広告の植木です。代理店様や広告主様に向けた広告効果のレポート機能のバックエンド開発を担当しています。
先日、 Yahoo! JAPAN Tech Conference 2019 in Shibuyaにて「YDNレポートジョブ渋滞に機械学習でたちむかってみた」というタイトルで、処理待ち時間を改善する取り組みの経緯について発表してきましたのでその内容をご紹介します。
取組みに至った経緯
レポート作成は数秒で終わるものもあれば、数時間に及ぶものまであるため、作成処理と作成リクエスト受付WebAPIとを分離し、Message Queueを用いた非同期の仕組みを採用しています。
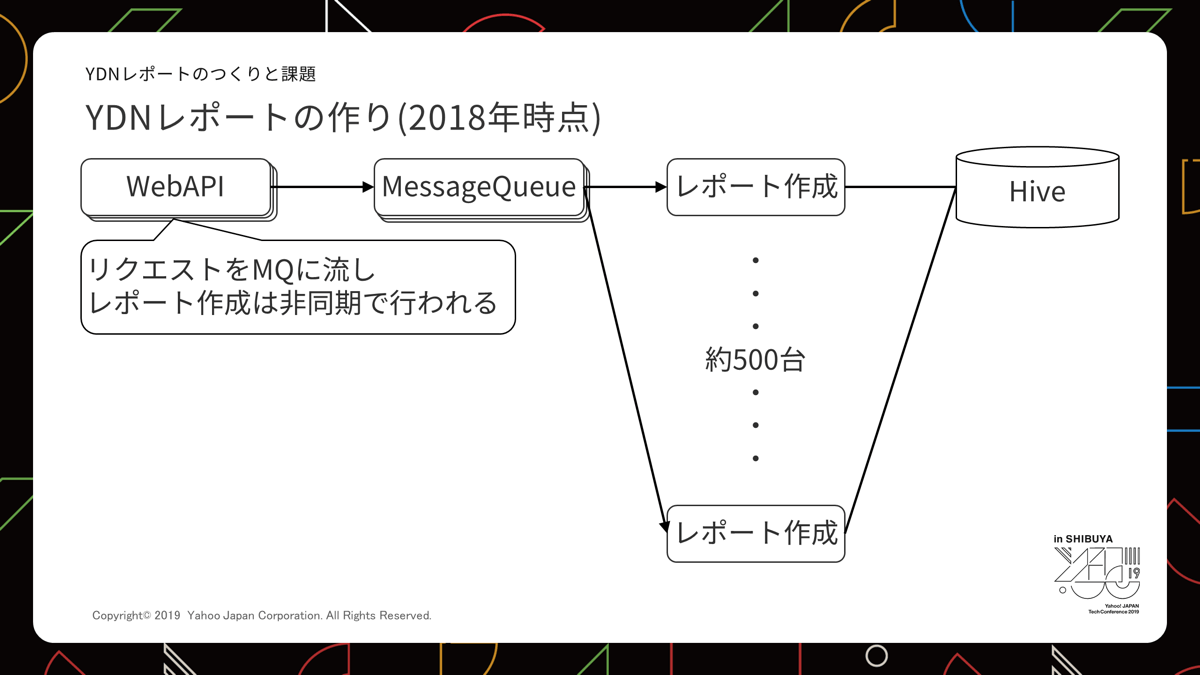 特定の広告アカウント(広告主や代理店のためのID)で処理サーバーが占有されることがないよう、ジョブの同時実行数の制限はかけているものの、ある時大量アカウントで数時間かかるジョブが投入されました。
すると処理できる空きサーバーがなくなってしまい、数秒で終わるはずのジョブが待たされて数時間かかってしまうという事態になりました。
特定の広告アカウント(広告主や代理店のためのID)で処理サーバーが占有されることがないよう、ジョブの同時実行数の制限はかけているものの、ある時大量アカウントで数時間かかるジョブが投入されました。
すると処理できる空きサーバーがなくなってしまい、数秒で終わるはずのジョブが待たされて数時間かかってしまうという事態になりました。
まさにジョブの渋滞発生です。
絵にするとこの様な感じです。分かりやすくするために処理するサーバーを3台にして表現しています。

この事態をなんとか防げないかということで対策を始めました。
最初は機械学習なんて考えていなかった
試行錯誤第一形態
最初に思いついたのは、「初めに件数を取得してからその量に応じてMessage Queueを振り分ける」というアイデアでした。
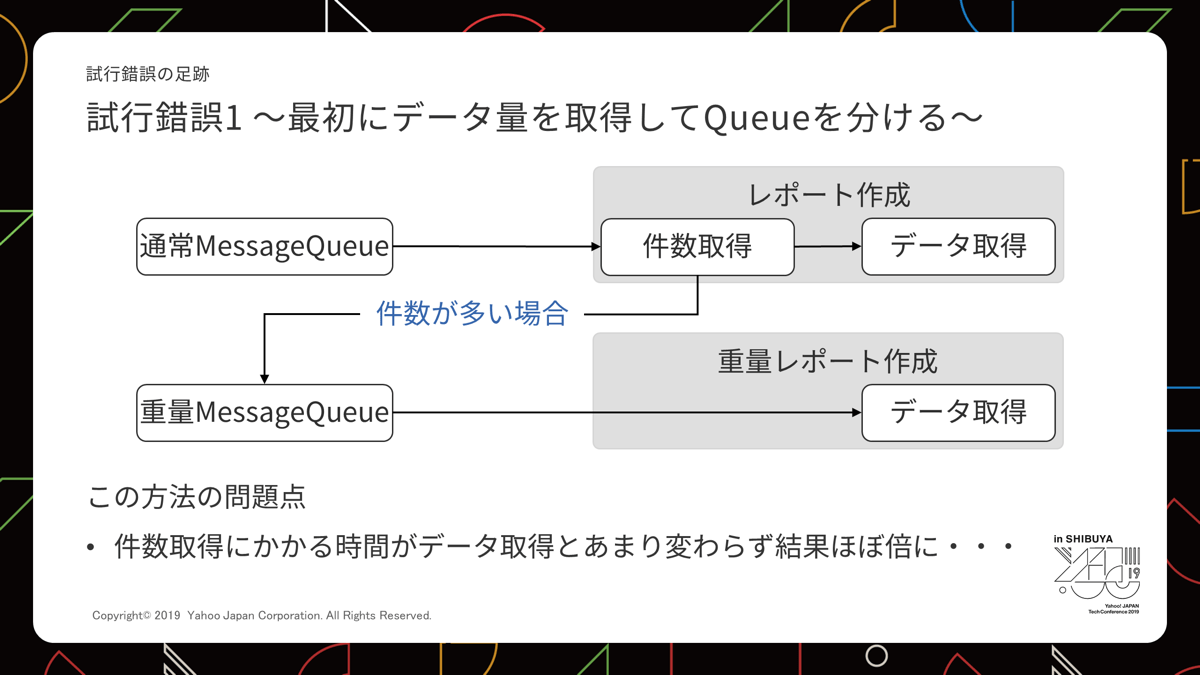
しかし、実際試してみるとデータ自体の取得と件数取得にかかる時間がほぼ同じという残念な結果となりました。
試行錯誤第二形態
次に、「データ取得時にタイムアウトを設けて時間がかかったものを別のMessage Queueに入れ直す」というアイデアを検討しました。
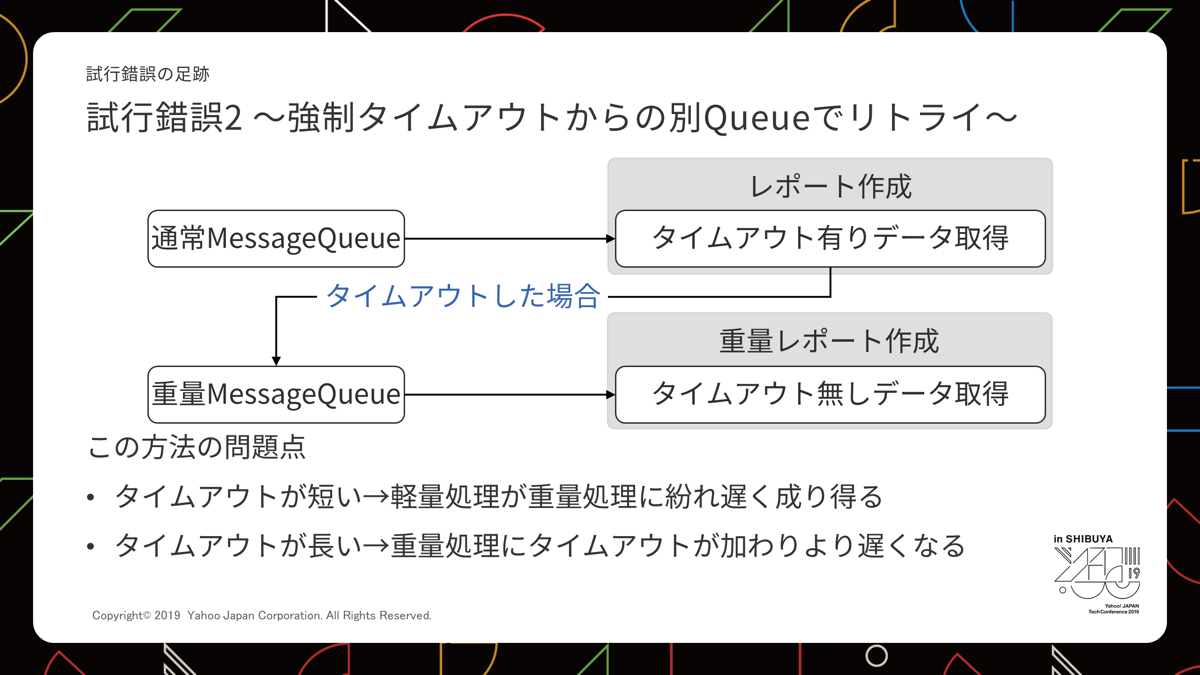
仕組みとしては簡単に実現できるので、アイデアとして悪くはなかったのですが、渋滞を発生させないためのタイムアウトの設定時間がとても難しいことに気が付きました。
例えば‥
- 5秒間に設定した場合
6秒~数分程度のジョブが重量Message Queueへ流れる。数時間のジョブと一緒に処理されるので結局渋滞が発生する。 - 1分間に設定した場合
1と基本的に同じ。それに加え1分1秒のジョブは2分1秒かかってしまうことになる。 - 30分間に設定した場合
2と基本的に同じ。ギリギリアウトのものも同じように倍になり現状よりひどくなるかもしれない。 - 1時間に設定した場合
30分~1時間程度のジョブが大量に投入されると渋滞が発生する。
処理時間にばらつきがあり、どう設定しても悪化させてしまうリスクが高いため採用できませんでした。
試行錯誤第三形態
さらに考えを進めて「そもそも渋滞が起きるときはそれなりに遅いジョブを大量投下していて同時実行数も多くなっているだろう」という仮説にたどりつきました。
ということで「同時実行数を制限して、オーバーした場合に別のMessage Queueに入れ直す」というアイデアを検討しました。
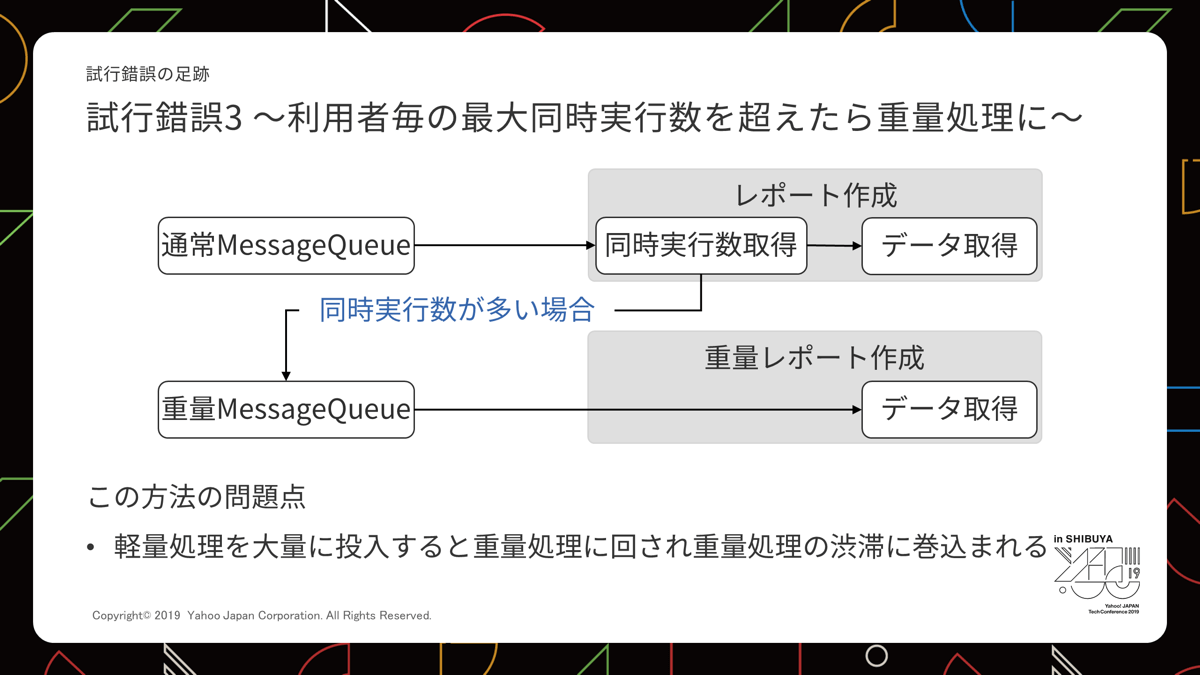 しかしこれにも課題がありました。
しかしこれにも課題がありました。
- 同時実行数の制限が大きめ
ばらけた広告アカウントでそれなりに遅いジョブが大量投下された場合、渋滞が発生する。今回の課題と同じケース。 - 同時実行数の制限が小さめ
数分のジョブが渋滞にはまる。
いろいろ検討はしましたが、結局件数を先読みする方法を考えるしかないという答えに至りました。
件数の先読み ⇒ 軽い重いの先読み
データ取得前に件数を取得する方法では、処理時間はほぼ倍になるだけです。
ならばデータ取得パターンから推測できないかと考えるようになりました。
そこで、最近の若手エンジニアの強みである機械学習のスキルを活かし、彼らを中心にこの問題に取り組んでもらうことにしました。
調査を進めていくと、われわれの持つインプットデータや結果のばらつきから、件数ではなく、処理時間の大小を推測するほうが精度が出るということが分かりました。
試行錯誤第四形態
仮に先読みできたとして、他に課題はないのか検討したかったのでここで第四形態を考えてみました。
「夢の箱」というのは重量か軽量か判定してくれる仕組みです。
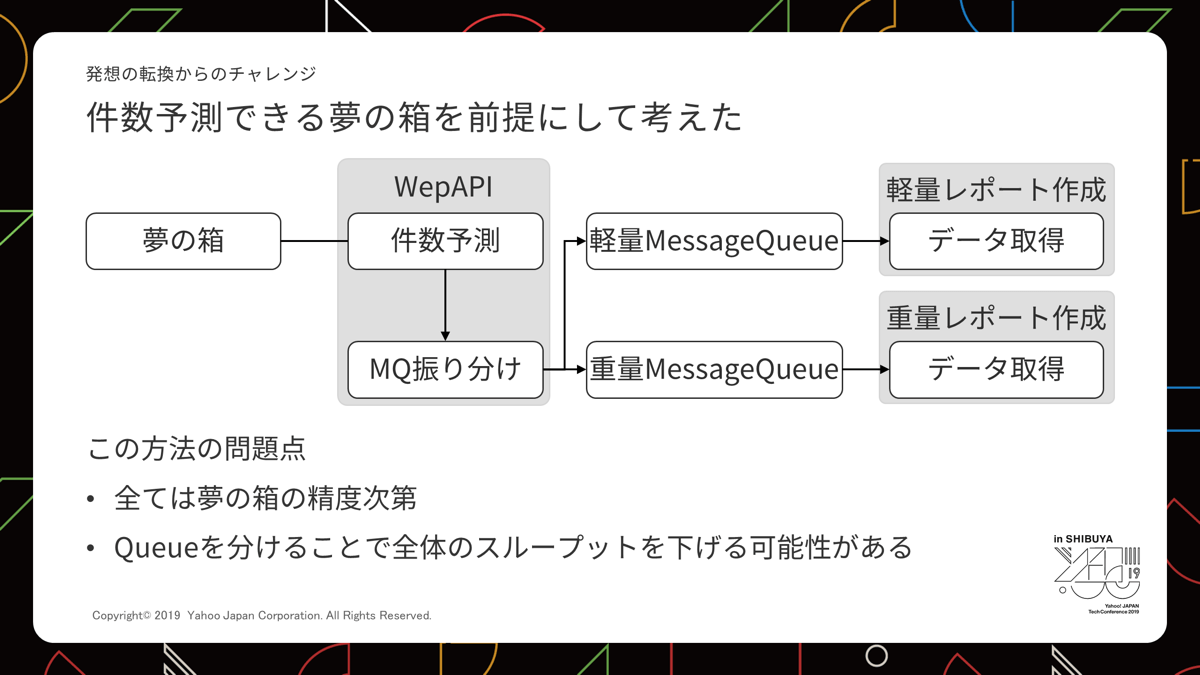 図としては単純なものになりました。先読みした結果、処理サーバーを完全に分離する必要が出てきました。ここでもし軽量、重量の偏りが想定外のものだと、全体のスループットを下げてしまう課題が生まれました。
図としては単純なものになりました。先読みした結果、処理サーバーを完全に分離する必要が出てきました。ここでもし軽量、重量の偏りが想定外のものだと、全体のスループットを下げてしまう課題が生まれました。
これについては Polled Consumersという仕組みを利用し解決しました。
レポート作成はMessage QueueのConsumerに当たりますが、これの重量の方を2つのQueueから受け取れるようにし、重量がないときだけ軽量を作成する2役を担ってもらうという仕組みです。
機械学習に向けて
どの要素がどう影響しているか、人が判定していたのではいつまでたっても終わりません。これを機械にやってもらうというのが発端です。
分野によっては最近は深層学習を採用しているケースが増えていますが、今回はオールラウンダーと言われているランダムフォレストを採用しました。
機械にデータを投入し、影響度の強いものを上部にした木構造を構築します。
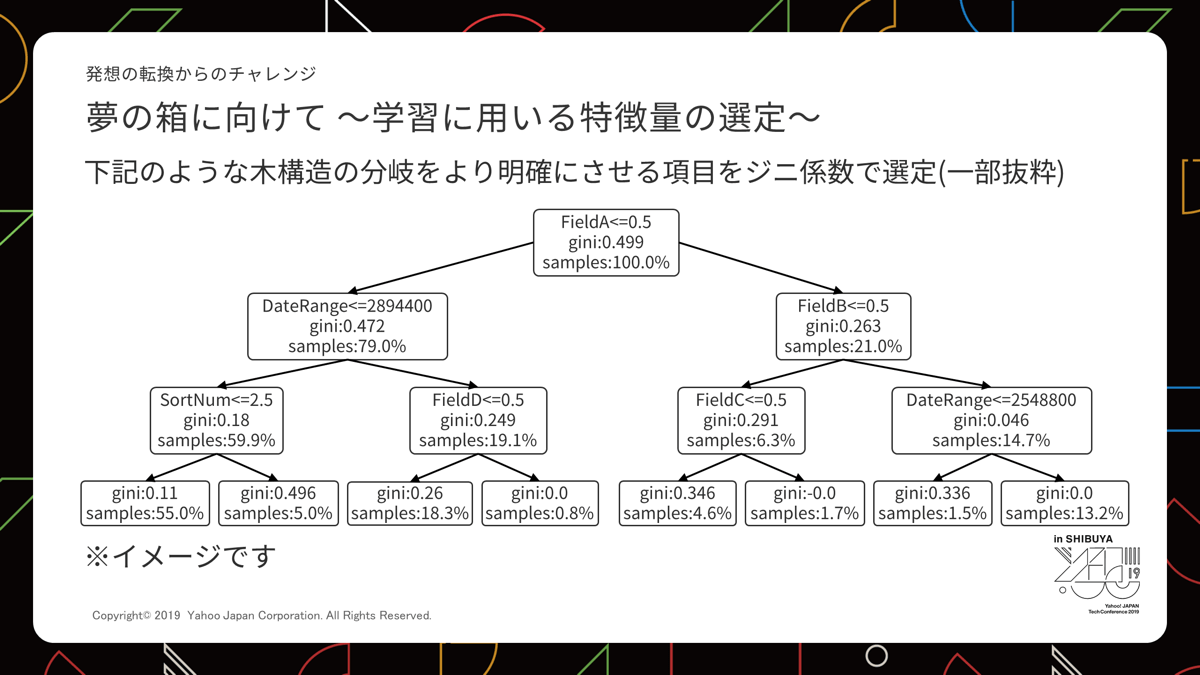 この木構造は学習のたびに使うデータをランダムに変えるので同じデータセットでも投入するたび微妙に変化します。
この木構造は学習のたびに使うデータをランダムに変えるので同じデータセットでも投入するたび微妙に変化します。
今回は3個分の木構造を用意しました。木構造はそれぞれ軽量ならどの分岐、重量ならどの分岐というパターンを保持しています。
データを3個の木構造に通し、結果どちらのパターンになったかの多数決で軽いか重たいかを判定します。
このように作った分岐ロジックをモデルと呼びます。
次にモデルの精度を測るための手法を検討しました。今回は混合行列を元にAccuracyとAUCという手法で精度検証しています。
 Accuracyは2つの正判定のうち、片方が異常に高いと残りが少し低くても精度としては高いと認識してしまいます。
この誤認識を防ぐため、どれだけ誤判定が少なかったかという観点で見るAUCで補っています。
Accuracyは2つの正判定のうち、片方が異常に高いと残りが少し低くても精度としては高いと認識してしまいます。
この誤認識を防ぐため、どれだけ誤判定が少なかったかという観点で見るAUCで補っています。
実際の1カ月分データで検証したところ、構築したモデルは高い精度で判定してくれました。
今回発生した重量ジョブが集中する事態は高頻度で発生するものではないため、過去データでの検証以上の効果は認められてはいません。しかし、導入後は、重量処理が増えやすい月末月初でも軽量処理が影響を受けることなく捌けるようになりました。

これで万事OK!
とはならず今後はモデルの自動更新を考えていかないといけません。
一方で、日がたつと別の課題も生まれました。
この取り組みと並行してレポートのデータ処理そのものを全体的に早くするという取り組みも行っていて、重量判定されたものでも数分で終わるケースが出てきました。
数時間かかっていたものが空いている時間帯は数分で取れる状態になったので、混んでいる時間帯だと遅くなったように感じる状況を作ってしまったのです。
インフラ面の強化に併せてモデルや形態を検討していかないといけないということに気づき、現在さらなる改善策を検討中です。
まとめ
今回の取組みは課題が残ったとはいえ、渋滞を減らす仕組みとしては期待値以上の結果が出せました。 遠慮なくチャレンジした若手エンジニアとうまく協力できた結果だと思います。
課題は残っているのであきらめず挑戦を続けたいと思います。
写真:アフロ
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 植木 和宏
- ヤフーディスプレイ広告 エンジニア
- 広告業務系バックエンド開発



