
こんにちは。
サービス統括本部の都筑(@kazuki229_dev)です。
新卒4年目で普段はYahoo! ID連携のサーバーサイド、iOSのSDKの開発などを担当しています。
Yahoo! ID連携とは、Yahoo! JAPANのシングルサインオンやユーザーの属性情報を取得するID連携の仕組みです。
このYahoo! ID連携ではPKCEというOAuth2.0の拡張仕様を実装しました。
https://developer.yahoo.co.jp/changelog/2019-12-12-yconnect.html
そこで、PKCEの基本的な話と、実装の際に調査したことをまとめてみました。
PKCEとは?
PKCEとは認可コード横取り攻撃の対策として提案された仕様です。
RFC7636(Proof Key for Code Exchange by OAuth Public Clients)として、2015年9月に発行されています。
今回Yahoo! ID連携にもこのPKCEを導入することで、より安全にクライアントを実装していただけるような選択肢が増えました。
認可コード横取り攻撃
まずは認可コード横取り攻撃について説明します。
認可コード横取り攻撃とは、Public Clientに対して発行された認可コードを取得し、それを用いてアクセストークンなどのトークンを不正に取得する攻撃です。
例を見ていきます。
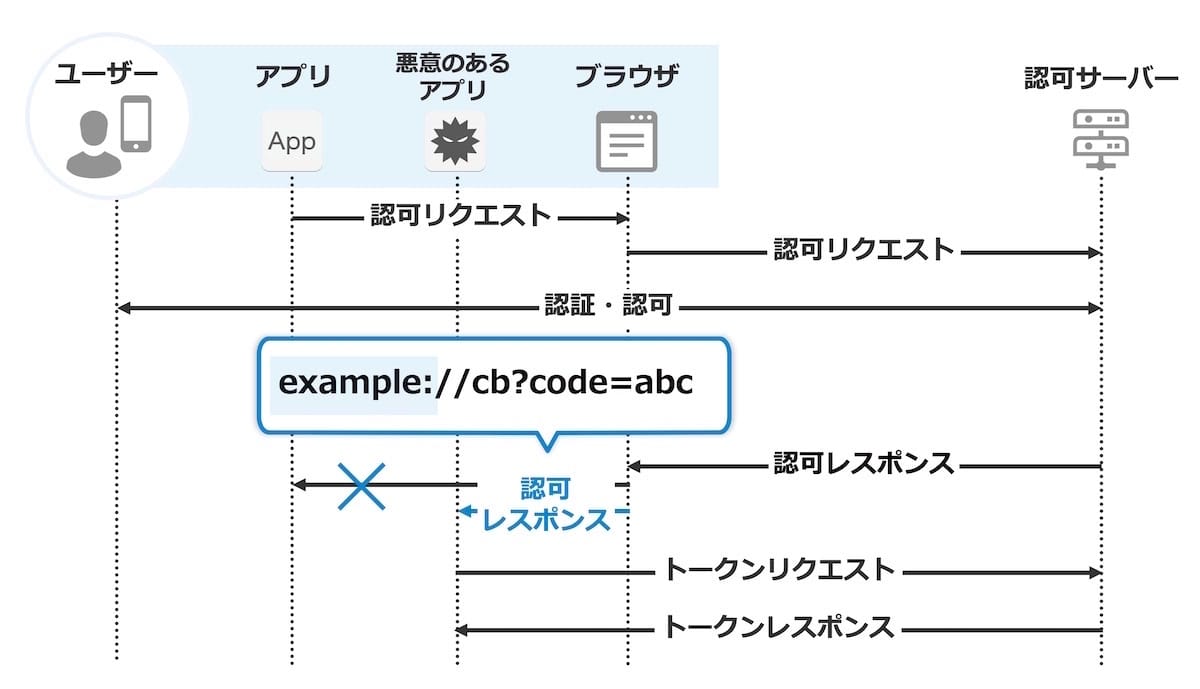
クライアントと攻撃者は下記のような状況であることが前提です。
- アプリはリダイレクトURIとしてカスタムURIスキームを利用
- 攻撃対象のアプリのカスタムURIスキームを悪意あるアプリが登録し起動可能な状態
カスタムURIスキームはブラウザーで開くとOSを介してアプリが起動しますが、アプリ実装者はスキームとして任意の値が指定できます。 したがって複数のアプリで同じスキームを利用することが可能です。 これにより、悪意のあるアプリは被害アプリが起動するはずのタイミングで自分のアプリを起動させるように仕向けます。
このような状況だと、認可レスポンスが悪意のあるアプリにわたり、認可コードを取得されてしまいます。
ネイティブアプリではクライアント認証ができないため、悪意のあるアプリはトークンエンドポイントへ認可コードをわたすことで、アクセストークンやリフレッシュトークンなどを不正に発行することができてしまいます。
この問題を解決する仕様がこのPKCEです。
PKCEでの認可コード横取り攻撃対策
次に、基本的なPKCEの動作を説明します。
PKCEでは認可エンドポイントと、トークンエンドポイントに下記のパラメータが追加されています。
認可エンドポイント
code_challengecode_challenge_method
トークンエンドポイント
code_verifier
これらのパラメータを利用した認可コードフローを順番に追ってみていきます。
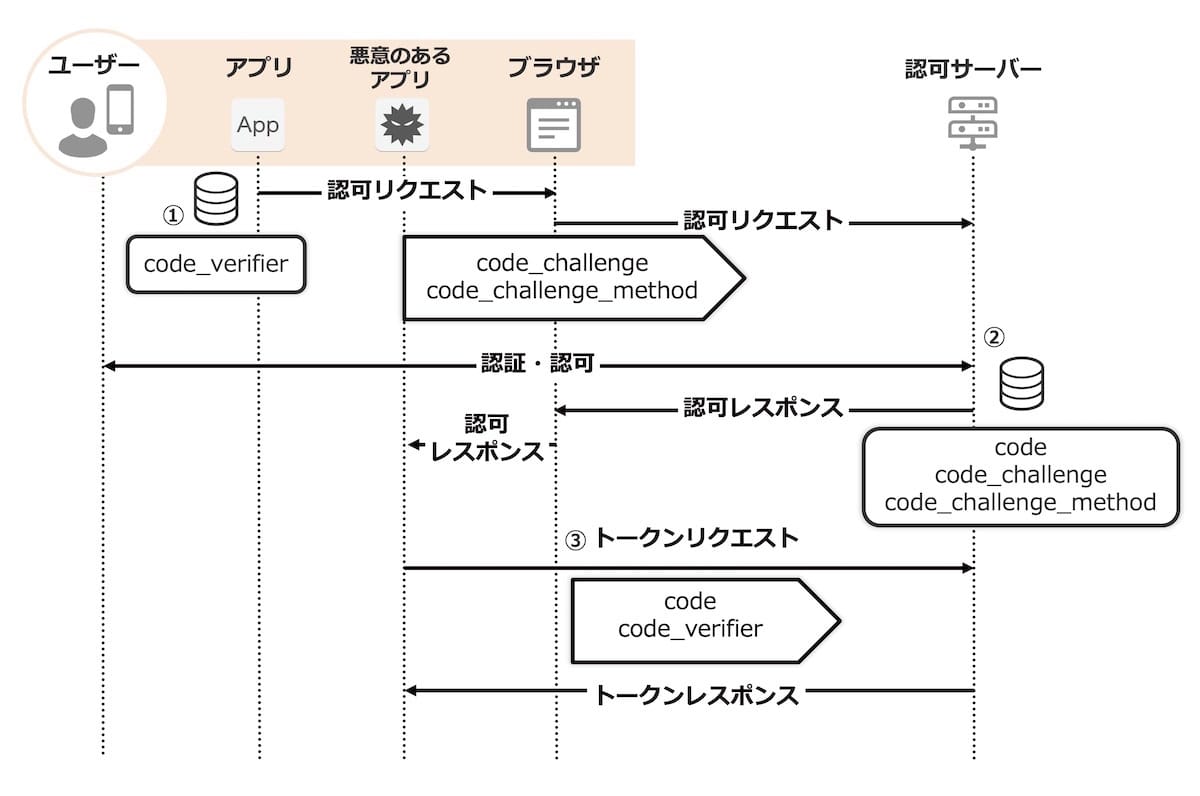
クライアントは
code_verifierを生成し保存します。code_challenge_methodで指定した方法でcode_verifierからcode_challengeを生成します。code_challenge_methodにはplainとS256という値が利用可能です。plainの場合はcode_verifierをそのままcode_challengeとして利用し、S256の場合はcode_verifierをSHA256で計算した値をcode_challengeとして利用します。 認可リクエストではこのcode_challengeとcode_challenge_methodを送信します。送信されたリクエストが正しければ、認証・認可後に認可サーバーは認可コードを発行します。 この際に認可サーバーは、認可コードとひもづけて
code_challengeとcode_challenge_methodを保存します。 保存したら認可レスポンスとして認可コードを返却します。クライアントは認可レスポンスをうけとったら、トークンリクエスト時に
code_verifierと認可コードを一緒に送ります。 認可サーバーは送られてきた認可コードにひもづけて保存しているcode_challenge_methodの方式でトークンリクエストで送信されたcode_verifierを変換し、その結果が認可コードにひもづけて保存しているcode_challengeと一致することを確認します。
以上の確認から、認可リクエストの送信者とトークンリクエストの送信者が一致していることを保証しています。
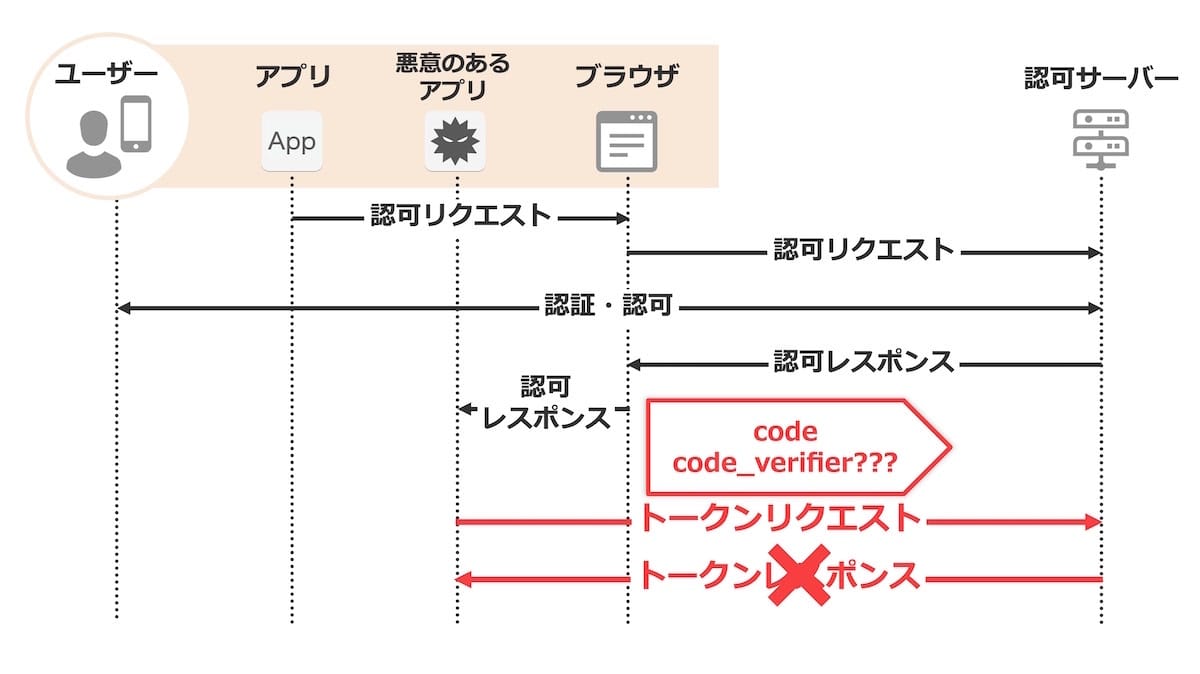
悪意あるアプリは認可コードの取得までは行えますが、一緒に送らなくてはならないcode_verifierの値がわからないので、トークンリクエストに失敗します。
以上のような仕組みでPKCEは認可コード横取り攻撃を防ぎます。
PKCEに対する攻撃
PKCEの仕組みがある上で攻撃者ができうる攻撃は、不正に取得した認可コードに対応するcode_verifierを推測し、トークンリクエストに送信することです。
PKCEの仕様上では攻撃者が可能な行動によって、2種類の攻撃者を想定しています。
- 認可レスポンスのみを観測可能な場合
- 認可リクエストと認可レスポンスを観測可能な場合
認可レスポンスはカスタムURIスキームの乗っ取りなど、認可リクエストはOSのログなどから観測可能である場合があると例では挙げられています。
1の場合は攻撃者はオンライン攻撃のみを行うことができます。 2の場合はオフライン攻撃が可能なので、1の場合よりもより強固な対策が必要です。
ではそれぞれの攻撃方法についてみていきます。
オンライン攻撃
オンライン攻撃は一番単純な方法で、認可コードを取得した悪意あるクライアントが、その認可コードとひもづくcode_verifierを推測し、トークンエンドポイントにリクエストをする方法です。
この攻撃はcode_challenge_methodの値がplainとS256の両方の場合で防ぐことができます。
ヒントのない状態から認可コードと対応するcode_verifierの値を当てなければいけないため総当たり攻撃をするしかありません。
答え合わせは実際にトークンエンドポイントへ認可コードとcode_verifierを投げつけてアクセストークンが取得できるかを確認するしかないため、認可コードが有効である期間内に行える試行回数としてはそこまで多くはありません。
ちなみにRFC6749 Section-4.1.2では認可コードの有効期間は最大10分とすることが推奨されています。
A maximum authorization code lifetime of 10 minutes is RECOMMENDED.
オフライン攻撃
オフライン攻撃はオンライン攻撃より高度な攻撃方法で、認可リクエストと認可レスポンスの両方を観測できる場合にのみ実行できます。
この場合、code_challengeとcode_challenge_methodを観測できているため、code_challenge_methodで変換するとcode_challengeとなるような値をトークンエンドポイントへリクエストすることなく、手元で探索することが可能です。
したがってcode_challenge_methodがplainの場合、code_challenge = code_verifierとなるため、この攻撃は防ぐことはできません。
ここまでの攻撃を想定するのであれば、code_challenge_methodをS256とするべきです。
オフライン攻撃はオンライン攻撃に比べ格段に総当たり攻撃の試行回数を増やすことができてしまいます。
そこでcode_challenge_methodをS256とすることで、code_challengeが観測できたとしてもSHA256を用いて計算されたcode_challengeの値からcode_verifierを探り当てることは困難なため、オフライン攻撃も防ぐことができるというわけです。
以上を踏まえて、S256を実装できる場合は必ずcode_challenge_methodをS256として実装するようにしましょう。
ここまでで、認可コード横取り攻撃の説明、それを防ぐPKCEの説明、PKCEの仕様に対する攻撃についてみていきました。
次にcode_verifierの仕様について詳しくみていきたいと思います。
code_verifierとは
code_verifierとはPKCEの鍵となるパラメータで、PKCEはcode_verifierが推測・計算されないという事実を元にしたセキュリティモデルとなっています。
RFC7636 Section-4.1では、code_verifierの説明がされています。
codeverifier = high-entropy cryptographic random STRING using the unreserved characters [A-Z] / [a-z] / [0-9] / "-" / "." / "\" / "~" from Section 2.3 of [RFC3986], with a minimum length of 43 characters and a maximum length of 128 characters.
code_verifierは43文字以上、128文字以下の文字列で、構成文字は[A-Z]/[a-z]/[0-9]/"-"/"."/"_"/"~"となっています。
NOTE: The code verifier SHOULD have enough entropy to make it impractical to guess the value. It is RECOMMENDED that the output of a suitable random number generator be used to create a 32-octet sequence. The octet sequence is then base64url-encoded to produce a 43-octet URL safe string to use as the code verifier.
また、クライアントは推測されないほど十分なエントロピーを持ったcode_verifierを生成すべきで、推奨される生成方法も記載されています。
- 適切な乱数生成器を用いて32オクテットのランダムオクテット列を生成
- 生成したオクテット列をBase64URLエンコード
ちなみにRFCでよく出てくるオクテットというのは8ビットの事です。
また、RFC7636 Section-7.1を見てみると下記のような記述があります。
The client SHOULD create a "code_verifier" with a minimum of 256 bits of entropy.
クライアントは少なくとも256ビットのエントロピーを満たすcode_verifierを生成すべきとの記述があります。
まとめると
- PKCEでは
code_verifierを推測されてはいけない
そのためにcode_verifierは下記の要件を満たす必要があるということです。
- 構成文字種が[A-Z]/[a-z]/[0-9]/"-"/"."/"_"/"~"
- 十分なエントロピー(256ビット以上)
- 適切な乱数生成器を用いて生成
例としてSwiftでのcode_verifier生成方法を載せておきます。
var bytes = [Int8].init(repeating: 0, count: 32)
// 安全な方法で乱数を生成
guard SecRandomCopyBytes(kSecRandomDefault, bytes.count, &bytes) == errSecSuccess else {
// error handling
return
}
// 生成したデータをBase64URLエンコード
let codeVerifier = Data(bytes: bytes, count: bytes.count)
.base64EncodedString()
.replacingOccurrences(of: "+", with: "-")
.replacingOccurrences(of: "/", with: "_")
.replacingOccurrences(of: "=", with: "")さらに調べてみました
いくつか疑問が湧いたので1つずつ解消していきます。
code_verifierはなぜ43~128文字なのか?
まず43という数字が中途半端に感じ、なぜ43文字以上なのかを調査しました。
code_verifierは43文字以上、128文字以下の文字列で、構成文字は[A-Z]/[a-z]/[0-9]/"-"/"."/"_"/"~"となっています。クライアントは少なくとも256ビットのエントロピーを満たす
code_verifierを生成すべきとの記述があります。
整理すると、code_verifierは66種類の文字から構成された文字列で、かつ少なくとも256ビットのエントロピーとすべきものです。
256ビットのエントロピーとは、すなわち組み合わせが2^256通りになるという事です。
計算してみると下記のようになります。
- 66^42 ≒ 2.6353924e+76
- 2^256 ≒ 1.1579209e+77
- 66^43 ≒ 1.739359e+78
したがって66^42 < 2^256 < 66^43というのが成り立つので、code_verifierは最低43文字あればよいと定義されているのです。
スッキリしました。
次になぜ128文字以下となっているのかを調べました。
これはメーリングリストを追ってみると記述があります。
https://mailarchive.ietf.org/arch/msg/oauth/UwC04uPWq-w2NY4Kl-xGZgllLd4
We limit the string size to 128 octets to limit the storage burden on the AS and to prevent the URI from becoming to long. longer than 128 characters adds no real value for those transforms and is enough for a SHA512 hash if someone wants to define that transform at some point in the future.
認可サーバーのストレージ負荷を制限するためと、URIが長くなることを防ぐためだそうです。
また128文字以上にしても特に効果は得られないとのことです。
まとめると、下記の理由から43~128文字となっているようです。
- 66種類の文字で構成された文字列のエントロピーを2^256以上にするためには少なくとも43文字以上必要だから
code_verifierの文字列長は128文字以上長くしても特に効果がない
32オクテットをBase64URLエンコードしたら43文字になるのか?
Base64URLエンコードはBase64エンコードでパディングとして追加した"="を取り除く処理が入るため、本当に32オクテットのビット列をエンコードした結果が43文字以上になるのでしょうか。
実際に社内での開発時にコードレビューで質問を受けた際に説明したので、確認方法を記しておきます。
Base64URLエンコードのエンコード方式は下記のような順番で行われます。
- ビット列を6ビットずつのかたまりでわける
- ビット数が6で割り切れるように0でパディングする
- 6ビットのかたまりを変換表を元に変換していく
- 変換し終わった文字列を4文字ごとのかたまりにわける
- 文字数が4で割り切れるように"="でパディングする
- "+"を"-"に、"/"を"_"に置き換え、"="を削除する
では1つずつ工程を見ていきます。
code_verifierでは32オクテットの乱数となるため、
下記のようなビット列を生成したとします。
10001101 00101111 11011111 11010111 10010100 10111101 00100100 10011111 11011001 00110111 00001010 01110000 00000111 11110010 11101101 00000001 01111110 10010101 10101101 11110110 01010000 11110111 01011010 01111001 10111000 10110110 01100001 01001000 10101111 01010011 00001100 10001010256個の0と1になりました。
1. ビット列を6ビットずつのかたまりでわける
100011 010010 111111 011111 110101 111001 010010 111101 001001 001001 111111 011001 001101 110000 101001 110000 000001 111111 001011 101101 000000 010111 111010 010101 101011 011111 011001 010000 111101 110101 101001 111001 101110 001011 011001 100001 010010 001010 111101 010011 000011 001000 10102. ビット数が6で割り切れるように0でパディングする
2ビット足りないので、0を2つ付け足します。
100011 010010 111111 011111 110101 111001 010010 111101 001001 001001 111111 011001 001101 110000 101001 110000 000001 111111 001011 101101 000000 010111 111010 010101 101011 011111 011001 010000 111101 110101 101001 111001 101110 001011 011001 100001 010010 001010 111101 010011 000011 001000 1010003. 6ビットのかたまりを変換表を元に変換していく
これを変換表に従って変換していくと、[A-Z]/[a-z]/[0-9]/"+"/"/"のいずれかの文字が43個となります。
j S / f 1 5 S 9 J J / Z N w p w B / L t A X 6 V r f Z Q 9 1 p 5 u L Z h S K 9 T D I o4. 変換し終わった文字列を4文字ごとのかたまりにわける
jS/f 15S9 JJ/Z Nwpw B/Lt AX6V rfZQ 91p5 uLZh SK9T DIo5. 文字数が4で割り切れるように"="でパディングする
1つ足りないので"="でパディングをします。
jS/f 15S9 JJ/Z Nwpw B/Lt AX6V rfZQ 91p5 uLZh SK9T DIo=これでbase64の文字列が完成します。
6. "+"を"-"に、"/"を"_"に置き換え、"="を削除する
jS_f15S9JJ_ZNwpwB_LtAX6VrfZQ91p5uLZhSK9TDIo以上の工程を振り返ると、3の工程の時点で必ず43文字は確保できるため、32オクテットをBase64URLエンコードすると必ず43文字になることがわかりました。
余談ですが、PKCEのドラフト段階のドキュメントでは、バージョン9まではcode_verifierは42文字以上となっており、その後の指摘でバージョン10に43文字以上と修正されました。
なぜ256ビット以上のエントロピーだと安全なのか?
RFC7636 Section-7.1では、code_verifierのエントロピーについて書かれており、256ビット以上のエントロピーにすべきとされています。
これについては、前述したオンライン攻撃とオフライン攻撃について分けて考えていきます。
オンライン攻撃を想定する場合、認可コードが有効な期間内でサーバーにどれだけ問い合わせられるかを考慮してエントロピーを決める必要があります。 したがって、認可コードのエントロピーと同じ考慮をすれば問題ないかと思います。 RFC6749 Section 10.10には認可コードのエントロピーについての記載があります。
I suggest to recommend at least 128 bits, which is inline with the recommendations for symmetric ciphers in http://tools.ietf.org/html/draft-ietf-uta-tls-bcp-07
ここでは少なくとも128ビットとなっています。256ビットではありませんでした。 では256ビットはどこから出てきたのでしょうか?
次にオフライン攻撃についてみていきます。 こちらは10分間に手元でSHA256の計算をして攻撃をします。
メーリングリストの下記言及では、オンライン攻撃は128ビットで十分、オフライン攻撃はSHA256に合わせてcode_verifierも256ビットでよいが、code_challenge_methodの値によってcode_verifierの長さ制限が変わることは実装上の混乱を招くとのことで、長い方に合わせて256ビットとされたようです。
https://mailarchive.ietf.org/arch/msg/oauth/hpTxKP5822-d4PRPavjqLlaLsNQ
32bytes was selected as a good value for S256.
...
I left it as 256bits for both to not introduce more options and not confuse people about why plain needs less entropy than S256.
まとめ
PKCEの概要から、細かい疑問の調査結果までをご紹介しました。
間違いや補足がありましたらコメントいただけるとうれしく思います。
RFCを隅々まで読んで実装するのがベストではありますが、すこしでもこの記事で仕様に理解を深め、実装の手助けになれば幸いです。
Yahoo! ID連携のiOS SDKをOSSとして公開したので、ぜひこちらも利用してフィードバックをいただければと思います。
https://github.com/yahoojapan/yjlogin-ios-sdk
今後も、みなさんのサービスにYahoo! ID連携を導入していただき、ユーザーによりよい体験を提供できるように努めていきますので、Yahoo! ID連携をよろしくお願いします。



