初めまして、2019年8月にヤフーのデータプラットフォームチームのインターンシップに参加した山添です。今回はインターンで検証を行ったカラムナフォーマットにおけるエンコーディング方式について紹介します。本ブログでは、特に数値型のエンコーディング方式について、データ圧縮率への効用を確認します。
カラムナフォーマットとは
昨今のデータ社会では、ログデータや購買データ、位置情報データなどさまざまなデータがものすごいスピードで生み出されています。企業ではそのような大規模なデータを蓄えておく必要があります。
私たち学生の間で最も親しみのあるファイルフォーマットは、JSON や CSV などのテキストフォーマットだと思います。これらのフォーマットは、データ保存時にスキーマを必要としない、人間からの可視性が高いなどの利点がありますが、データの圧縮効率が低いことや、処理性能の低さなどのデメリットもあります。
そこで、データの圧縮効率と利用効率を求めて提案されたのがカラムナフォーマットです。カラムナフォーマットは、大規模なデータを効率よく保存、利用するための仕組みで、圧縮効率が高いこととデータの利用効率が高いことが特長として挙げられます。カラムナフォーマットは、同じ属性のデータが集まる列方向にデータを圧縮することでデータの圧縮効率を高めることができます。また、必要な列のデータだけを取り出すことができるため、データの利用効率も高くなります。
カラムナフォーマットは Twitter 社が実装した Parquet や、Apache 社が実装した ORC が OSS で利用できますが、これらの実装ではデータ保存時にスキーマを必要とするため、テキストフォーマットの利点であったデータ保存時の気軽さが失われてしまいます。
ヤフー発の OSS 「Yosegi」
そこでヤフーでは、
- テキストフォーマットの利点であるデータ保存時の気軽さ
- カラムナフォーマットの利点であるデータの圧縮効率、利用効率
の 2点を両立したカラムナフォーマット OSS の Yosegi を開発しました。
Yosegi では ORC や Parquet にはない Expand & Flatten と呼ばれる技術を使ってネストデータを自動的に展開します。また、入力データに合わせてデータ構造を構築することによってスキーマレスな書き込みを実現しており、データ保存時の気軽さという面では ORC や Parquet に比べて優っていると言えます。
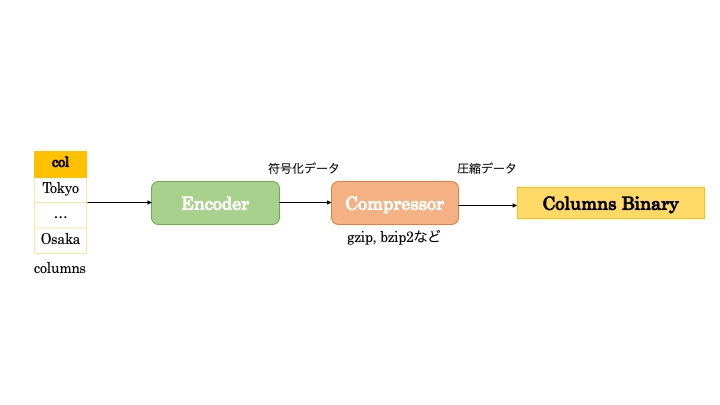
データ圧縮の流れ ~エンコーディングとは?~
ORC や Parquet、Yosegi のカラムナフォーマットのデータ圧縮では、まず、データの分布や統計量などに基づき最適な符号化が行われます。この符号化技術をエンコーディングと呼びます。エンコーディングによってデータに適した符号化でデータサイズを落とした後に、gzip や bzip2 などに代表される一般的な圧縮技術を適用します。カラムナフォーマットでは列単位でデータを圧縮するため、同じ属性のデータをまとめて符号化します。そのため、各列に最適なエンコーディング方式を選択できるメリットがあります。今回は、gzipなどの圧縮前に適用されるエンコーディング方式に着目しています。
データ型ごとのエンコーディング方式紹介
エンコーディング方式には各データ型に適した手法が存在しています。以下では代表的なエンコーディング方式を紹介します。特に数値型エンコーディングに焦点をおきました。
null 型
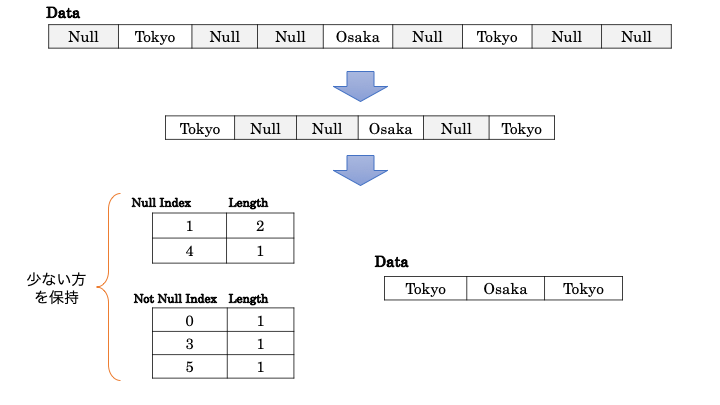
Null Suppression 方式
Null Suppression は null を含むデータに対する代表的なエンコーディング方式で、null の代わりに、null のインデックスと数を保持することによってデータを圧縮します。
Yosegi での null 処理
Yosegi での null 処理は Null Suppression とは少し違った方法を使っています。まず、先頭/末尾に null が存在する場合、最初の要素が出現するまで null をスキップすることでカラムサイズを少なくします。その後に null のインデックスを抽出し、null のインデックスと not null のインデックスを比較し、小さい方を保持します。そのためインデックスの数の最大値を要素数の半分にできます。
文字列型
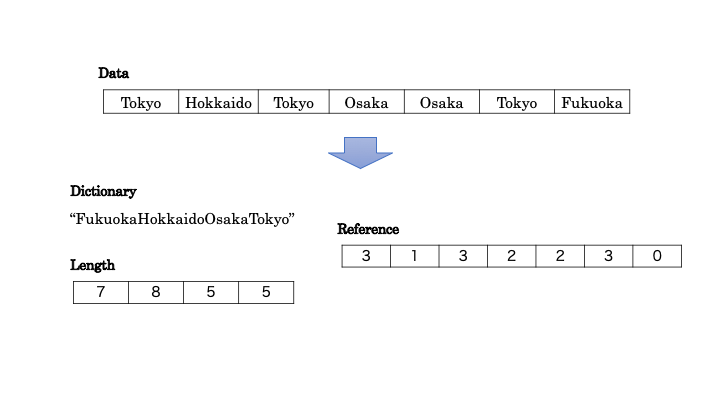
Dicitionary Encoding 方式
文字列型のエンコーディング方式の代表例は Dictionary Encoding です。Dictionary Encoding では、データからユニークな値をもとに辞書情報、文字長と参照情報を取得し、エンコードします。データのカーディナリティが低い場合にはうまく効きますが、カーディナリティが高くなるにつれて辞書情報が大きくなり、圧縮効率が低下してしまいます。カーディナリティとは、データに含まれるユニークな値の数を指します。
数値型
ZigZag 方式
ZigZag Encoding 方式は符号付き(signed)データのエンコードに適用されます。コンピュータではデータは 2進数で表現されるため、負の数を表現には最大のビット数が必要です。これは、明らかに非効率なので、signed を unsigned に変換することで、データの圧縮効率を高めます。具体的には、正の数と負の数を行ったり来たり(ジグザグに)変換します。つまり、-1 が 1 に、1 が 2 に、-2 が 3 に、...、とエンコードされます。
| オリジナル値 | エンコードした値 |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| ... | ..... |
| 100 | 200 |
| -101 | 201 |
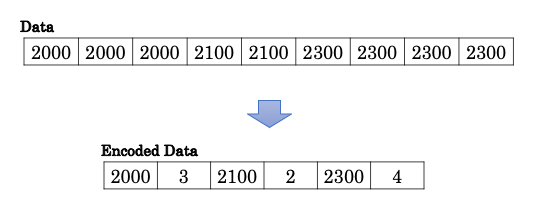
Run-Length Encoding 方式
Run-Length Encoding 方式は同じ値が連続するデータをまとめて保持する方法です。どんなデータが何回繰り返されたかを保持することで、データの圧縮効率を高めます。繰り返しの多いデータに適しており、数値型以外にも適用できます。
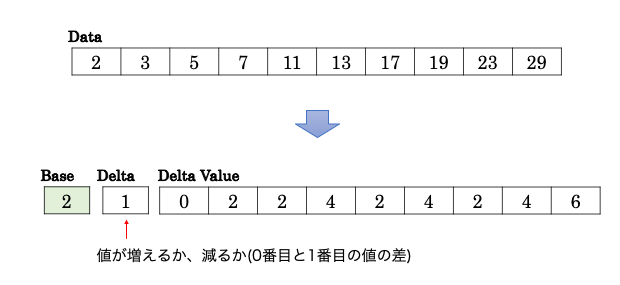
Delta Encoding 方式
Delta Encoding 方式は単調増加、単調減少するデータに適したエンコーディング方式です。ベースの値からの差を保持することで、データ圧縮効率を高めます。ヘッダーでベースの値と値が増加していくのか、減少していくのかを保持します。
Patched Base Encoding 方式
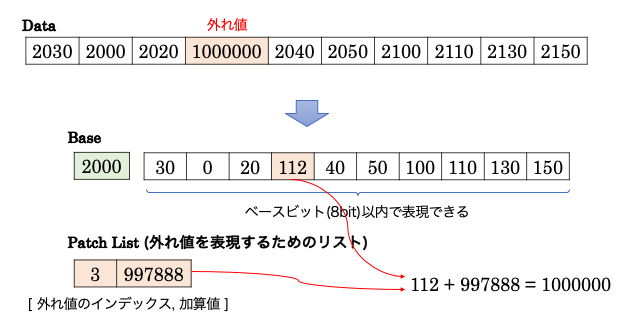
Patched Base Encoding 方式は、大部分のデータに対してあるビット数(W bit)を用いて表現可能な場合に効果を発揮します。全データの内 90% のデータが表現できるビット数をベースのビット数とし、他の 10% の外れ値データをパッチリストを用いることで補います。このような方法を取ることで、一番大きな数値にビット数を合わせる無駄を削減できます。
調査の狙い:圧縮効率のよい OSS を知りたい
Yosegi は、データ圧縮時に用いられるエンコーディング方式の充実度という面では ORC と Parquet に劣っています。今回はそれぞれの OSS のデータ圧縮効率の優れた点を明らかにするため、エンコーディング方式の充実度がデータ圧縮にどれほどの影響を及ぼすのか、またデータ圧縮効率の面で優劣があるのか、ORC/Parquet/Yosegi の 3種類で比較しました。
調査結果:方式別の圧縮効果
本節では、本題の数値型エンコーディング方式の比較をします。データ圧縮にもたらす効果を、疑似データを使って実験することで調査しました。
各 OSS に搭載されているエンコーディング方式(数値型)
先に、エンコーディング方式には各データ型に適した複数の手法があることを示しましたが、ORC, Parquet, Yosegi のそれぞれに全てのエンコーディング方式が実装されている訳ではありません。以下の表に各 OSS に実装されている数値型エンコーディング方式をまとめます。
| ORC | Parquet | Yosegi | |
|---|---|---|---|
| ZigZag 方式 | ◯ | ✕ | ✕ |
| Run-Length 方式 | ◯ | ◯ | ◯ |
| Delta 方式 | ◯ | ◯ | ◯ |
| Patched Base 方式 | ◯ | ✕ | ✕ |
ORC はエンコーディング方式の実装が豊富です。比べて Yosegi には Delta Encoding、Run-Length Encoding しか実装されていません。Yosegi はスキーマレスな書き込みが出来ることやExpand & Flatten など他の OSS にはない強みを持つカラムナフォーマットとして誕生した経緯もあり、エンコーディング方式については最低限の実装しかされていません。しかし実用上、データ圧縮率も重要な要素であることは間違いありません。
このことから、今回の目的として、上記のエンコーディング方式の充実度がデータ圧縮率にどれ程影響を与えるのかを明らかにすることとしました。以下では、エンコーディング方式が最も充実している ORC とヤフーの開発した Yosegi を使って、さまざまな特徴を持つデータを圧縮し、それぞれのデータ圧縮率にどれ程の差があるかを確認します。ORC と Yosegi にはそれぞれ、コマンドラインで動作する yosegi-tools、ORCの Java Tools が実装されており、これらのツールを用いて、データのエンコードと圧縮に伴うデータサイズの比較をしました。
一様分布なデータ
一様分布なデータには特に特徴がないため、どのエンコーディング方式も効果がない事になります。このことから、一様分布なデータにおける圧縮サイズを基準として、他のデータ分布における圧縮率を計算します。データサイズが 10KB、100KB、1MB となる一様分布データを作成し、ORC と Yosegi に変換した際のデータサイズを以下に示します。
| 未圧縮時データサイズ | ORC | Yosegi |
|---|---|---|
| 10 KB | 2,115 Byte | 1,977 Byte |
| 100 KB | 18,604 Byte | 16,377 Byte |
| 1 MB | 184,148 Byte | 160,422 Byte |
ORC および Yoaegi はデータフォーマットに必要な管理情報が含まれており、管理情報の差異がこのデータサイズの違いとして現れています。一様分布データはエンコードやデータ圧縮アルゴリズムによる圧縮効果が無いため、これらの値で標準化することで、Yosegi と ORC での各データに対するエンコードとデータ圧縮の違いを比較できます。
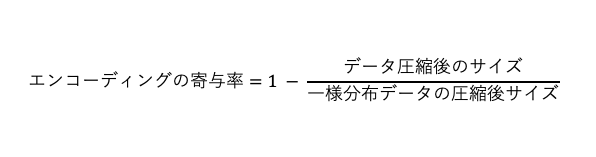
以下に、入力データに対するエンコードの寄与率を計算する方法を示します。
負の数を含むデータ(正規分布)
次に負の数を含むデータを圧縮します。
データとして、0 を平均とする正規分布を生成しました。負の数を含むデータには ZigZag Encoding が効くと考えられます。
| ORC | Yosegi | |
|---|---|---|
| 10 KB | 0.538 | 0.421 |
| 100 KB | 0.607 | 0.542 |
| 1 MB | 0.618 | 0.553 |
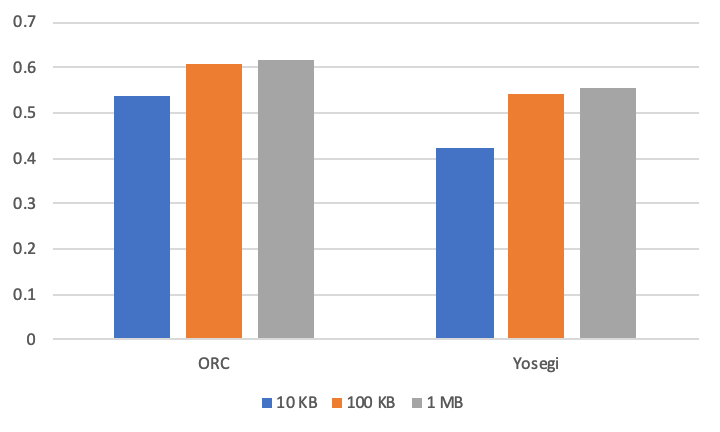
ZigZag Encoding が実装されている ORC のエンコーディングの寄与率が高いことが分かります。これと比較して Yosegi のエンコーディングの寄与率は若干低いものとなっています。
インクリメンタルなデータ
次にインクリメンタルなデータに対する圧縮効果を比較してみます。インクリメンタルなデータとして、
- 1ずつ単調増加するデータ
- ランダムに単調増加するデータ
- 稀に減少を含むデータ(全体の1%が前の値から減少する)
の3種類のデータを用いて実験しました。以下に結果を示します。
| (1) | (2) | (3) | ||||
|---|---|---|---|---|---|---|
| ORC | Yosegi | ORC | Yosegi | ORC | Yosegi | |
| 10KB | 0.898 | 0.399 | 0.758 | 0.348 | 0.437 | 0.316 |
| 100KB | 0.987 | 0.383 | 0.804 | 0.379 | 0.422 | 0.319 |
| 1MB | 0.997 | 0.378 | 0.795 | 0.389 | 0.304 | 0.324 |
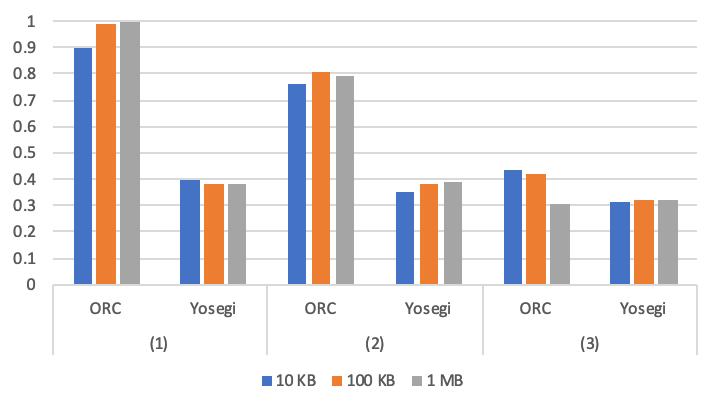
インクリメンタルなデータに対しては ORC の寄与率がかなり高いことが分かります。Delta Encoding が実装されていることで、データを効率よく圧縮できています。しかし、減少を含むデータに対してはうまく機能しないようです。
Yosegi にも Delta Encoding は実装されていますが、ORC が全データに対してで Delta Encoding するのに対して、Yosegi は一定の区分に対して Delta Encoding するため、寄与率が低くなっています。
繰り返しのあるデータ
次に、同じデータが連続するデータに対してフォーマット変換を行います。繰り返しのあるデータには Run-Length Encoding が効くことが予想されます。
| ORC | Yosegi | |
|---|---|---|
| 10KB | 0.892 | 0.793 |
| 100KB | 0.978 | 0.956 |
| 1MB | 0.989 | 0.977 |
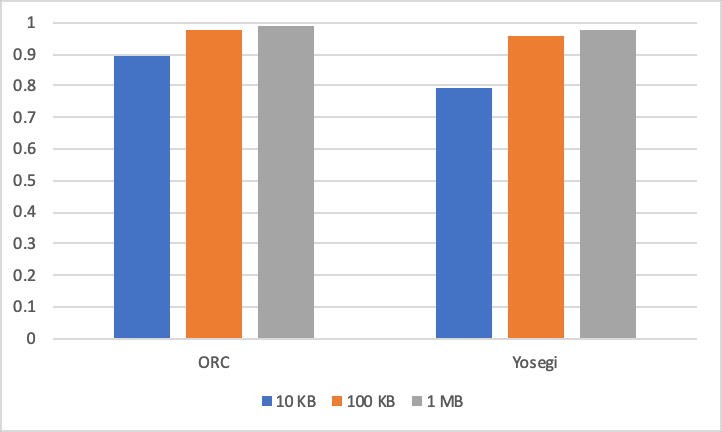
繰り返しのあるデータでは、ORC と Yosegi のエンコーディングの寄与率がほとんど同じ結果になりました。
外れ値を含むデータ
最後に、外れ値を含むデータに対する圧縮圧縮効果を測定します。データの外れ値が発生する割合を、1%、5%、10%に設定して実験しました。以下にそれぞれの結果を示します。
| 1% | 5% | 10% | ||||
|---|---|---|---|---|---|---|
| ORC | Yosegi | ORC | Yosegi | ORC | Yosegi | |
| 10KB | 0.642 | 0.390 | 0.437 | 0.345 | 0.317 | 0.312 |
| 100KB | 0.711 | 0.508 | 0.546 | 0.465 | 0.374 | 0.410 |
| 1MB | 0.717 | 0.524 | 0.523 | 0.479 | 0.382 | 0.426 |
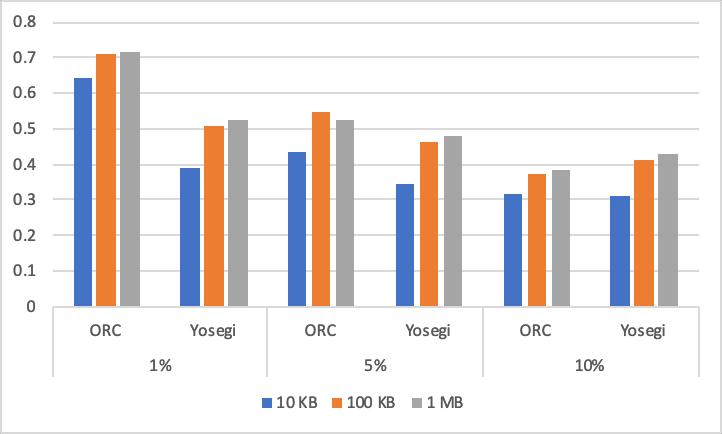
外れ値を含む割合が 1%のときには ORC のエンコーディングの寄与率が高くなる結果となりました。外れ値を含む割合が増えれば増えるほどエンコーディングの効果が低くなります。外れ値の割合が増えるとパッチリストのサイズが大きくなるので、予想通りの結果と言えます。
まとめ
調査の結果、インクリメンタルなデータや外れ値を含むデータには、それぞれに適したエンコーディング方式を用いる事でデータ圧縮に大きな効果があることが分かりました。
ORC はエンコーディングを強みとしており、実装されている手法が豊富です。Yosegi には Expand & Flatten というエンコーディングとは別の強みがありますが、エンコーディングもデータサイズの面で重要であることが明らかになりました。このようなことから、Yosegi はまだまだ伸び代のあるファイルフォーマットであるといえます。
Yosegi はオープンソースとして公開されています。今回行った調査結果をもとに、いろいろな方が知恵を出し合い、より良いものを作れていければ良いと思いました。
インターンシップ担当メンターより
今回のインターンシップで山添さんを担当した大戸です。
Yosegi はヤフー発の OSS として公開、開発が進められています。しかし、OSS は開発だけで簡潔するものではなく、多くの人に知ってもらい、同様の機能を持つ他の OSS と比較し、利用検討を行うためのドキュメントが必要になります。そして、ドキュメントの充実度が上がることで、利用者や OSS への貢献が増えていくことが期待できます。
山添さんは、今回の業務を通して、ヤフーの技術の一端に振れるのみならず、ドキュメント提供という形で OSS への貢献がどのようなものかを感じていただけたようです。
今後も、Yosegi を OSS として独り立ちできるような取り組みをしていきたいと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



