こんにちは、ヤフーで自然言語処理の研究開発をしている颯々野です。ヤフーでは、Yahoo!デベロッパーネットワークでテキスト解析Web APIを公開・提供しています。まず社内向けAPI、次いでこの公開APIと段階的に新インターフェースに移行し、2022年12月からは全てJSON-RPC 2.0に基づくものになりました。
2年前に言語処理APIのインターフェーズ共通化プロジェクト「Azuki」を進めていることを紹介しました。今回は、このプロジェクトがどうなったのかと、共通化によって得られたメリットなどをご紹介します。
インターフェース共通化を推進するプロジェクト「Azuki」
まず簡単にどんなものだったか振り返っておきます。詳細は前回の記事をご覧ください。
共通化の背景と目的
私たちは形態素解析やキーワード抽出など多くの機能を自分たちで開発、リリースしています (その一部はYahoo!デベロッパーネットワークでも テキスト解析Web API として公開)。それらの機能は多くのサービスで利用されています。
ところが提供する言語処理機能が増え、提供形態が多様化すると、機能本体の開発よりもそれに付随する多くの作業に時間が必要になりました。ここでいう付随する作業とは、ラッパーの作成やウェブAPIサーバの保守・維持、ドキュメントの作成などを指します。
また、提供する側からの上記の課題だけではなく、利用する側から見ても各機能がばらばらの仕様では学習コストが高くなってしまいます。
これらの課題を解決していくためにインターフェースの共通化の取り組みを進めました。
JSON-RPC 2.0 による共通化
言語処理の各機能の入出力のインタフェースをできるだけ共通にするためにJSON-RPC 2.0を採用しました。
下の画像は共通化後のリクエスト(入力)とレスポンス(出力)の例です。リクエストとレスポンスがいずれもJSONで記述されています。この例では、形態素解析とスペラー(スペル訂正)でリクエストがほぼ同じ形式になっています。どちらも処理対象となる文字列を “q” で指定しています。
「今日の天気は晴れです。」→「今日/の/天気/は/晴れ/です/。」
{
"id": "1",
"jsonrpc": "2.0",
"method": "tokenizer",
"params": {
"q": "今日の天気は晴れです。"
}
}{
"id": "1",
"jsonrpc": "2.0",
"result": {
"tokens": [
["今日","きょう","今日","名詞","時相名詞","*","*"],
["の","の","の","助詞","接続助詞","*","*"],
["天気","てんき","天気","名詞","普通名詞","*","*"],
["は","は","は","*","助詞","副助詞","*","*"],
["晴れ","はれ","晴れる","動詞","*","母音動詞","基本連用形"],
["です","です","だ","判定詞","*","判定詞","デス列基本形"],
["。","。""。","特殊","句点","*","*"]
]
}
}「コロナか」→「コロナ禍」
{
"id": "1",
"jsonrpc": "2.0",
"method": "speller",
"params": {
"q": "コロナか"
}
}{
"id": "1",
"jsonrpc": "2.0",
"result": {
"suggestions": [
"コロナ禍"
]
}
}先のリクエストとレスポンスの例はいずれもJSON-RPC 2.0に従う下記の形式になっています。

従来、形態素解析のライブラリAPIやWeb APIのインターフェースというと、解析対象や解析方法の指定や解析結果の利用の仕方を詳しく正確に知らなければ利用できませんでした。今回実現したJSON-RPC 2.0に基づく方法では、処理を指定する “method” の名前とリクエスト、レスポンスの JSON を理解すればよく、処理を実行し結果を得るところまでの手順は易しくなりました。この流れを理解すれば、形態素解析以外の他の処理 (例 スペラー) を利用する場合でも同じ方法が使えます。
その後の展開
前節で説明したインターフェースを持つWeb APIサーバを作って提供を始めています。各言語処理の機能は共有ライブラリ(shared library)のハンドラとして作成し、それをサーバにプラグインのようにして追加していきます。
2020年9月の段階では以下の二つでした。
その後、サーバのクラスタを増強しつつ多くの機能を追加していきました。10を超えるハンドラが作成され、実際に利用されています。一部を紹介します。
一つは機械学習による文書分類です。ツイートを機械学習で分類を行い、感情分析を行うAPIが稼働しています。感情分析の詳細はポジティブ?ネガティブ?ツイートの感情分析にBERTを活用した事例紹介 ? 学習データのラベル偏りに対する取り組みをご覧ください。
また、Yahoo!デベロッパーネットワークで公開しているテキスト解析Web APIも段階的に新インターフェースに移行し、2022年12月からは全てJSON-RPC 2.0に基づくものになりました。現在、以下の機能を提供しています。
これらのAPIではリクエストの形式、エラーの返し方などが全て同じになりました。説明のためのドキュメントも共通部分が増えました。以前はすべてがばらばらでした。同時に、スペラーを始めとする社内向けの種々の言語処理APIとも基本的な仕様が同じになったとことを意味します。
これらのAPIを提供しているサーバクラスタが処理するリクエストは順調に増え、2年で100倍になりました。スペラーが処理するYahoo!検索のクエリや感情分析が解析するツイートなどは膨大な数のリクエストになります。それでも大きな問題なく処理できています。
共通化で得られたメリット
インターフェースを共通化し、提供するWeb APIサーバクラスタ自体も共通化して進めてきました。この結果、以下のようなメリットが生まれました。
作成側では、どの言語処理機能を提供する場合でも、基本となる仕様、作成のための知識、公開の手順、基本となるドキュメント等が全て同じになり、効率化されました。 一通りの言語処理機能の本体が完成してから、サービスでの実運用に耐えるWeb API提供までの時間も大幅に短縮されました。大規模なリクエストをさばけるクラスタ本体はあるので、そこに追加する所定の形式の共有ライブラリを準備するだけで済むからです。
サーバを運用・維持する場面でも、サーバクラスタとしてまとまっているため、システムの構成・監視・運用などもまとまりました。脆弱性対応などもまとめて1回で済ませることが可能になりました。
また、プロジェクトごとにばらばらになりがちだった作業手順やシステムも同じ部分が増えました。これは副次的に大きなメリットをもたらします。システムや手順を改善すれば、共通のクラスタを使うAPI全てが良くなり、それにかかわるエンジニア皆がその改善を享受できます。システムの保守や維持は地味になりがちですが、その作業や改善を協力してやりやすくなりました。
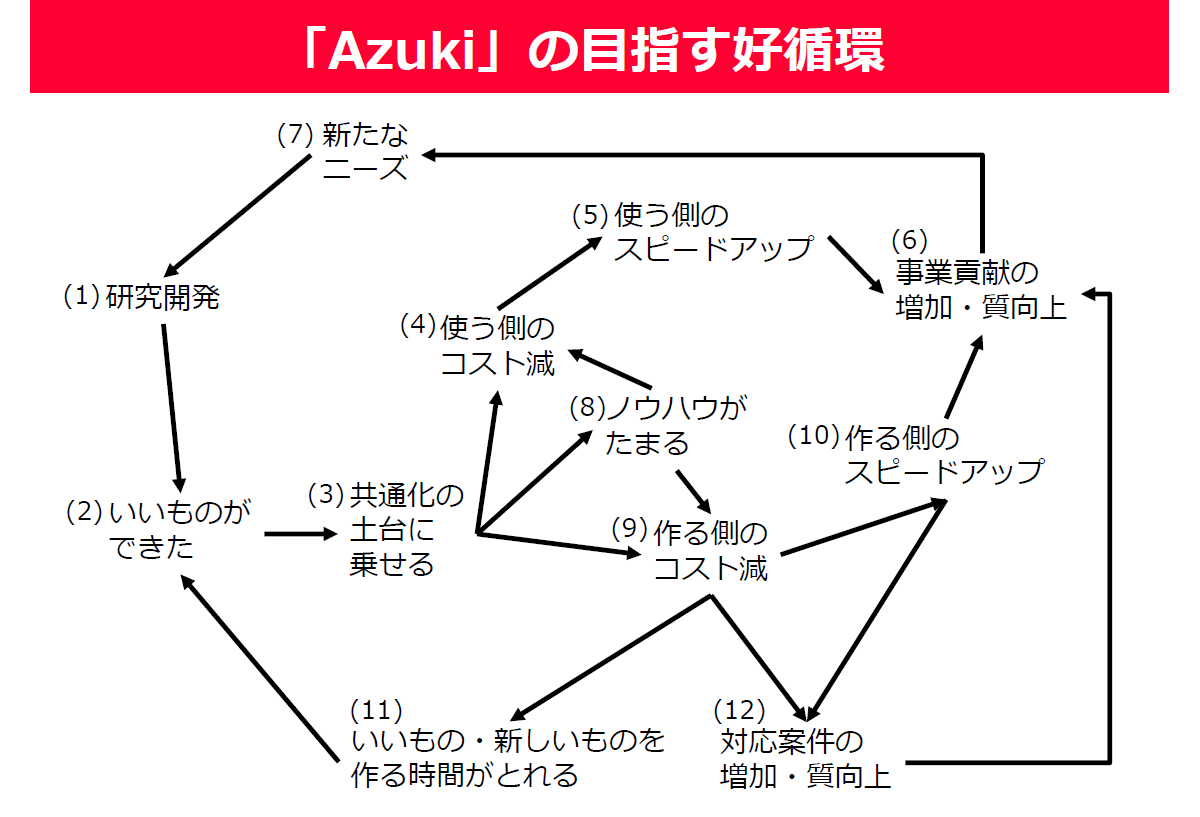
得られるメリットは相互に関係する複数の側面で多岐にわたることが分かります。これが以下の図のようにうまく循環して、よい研究開発、よい事業貢献が実現できることを期待しています。Yahoo!検索を始めとする各サービスでの利用が進みつつあります。この循環が回り出したことを実感しています。
おわりに
言語処理機能のインターフェースの共通化の取り組みの現在の状況を紹介しました。私たちは優れた性能や機能を持つ技術を開発するのに加えて、それを実際のサービスでも役に立つところまで持っていきたいと真剣に考えています。今回の共通化の取り組みによって着実に進んだと実感できました。今後も継続して共通化の仕組みの改善を行い、新しい言語処理の技術開発やサービスの改善にもつなげていきたいです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 颯々野 学
- Yahoo! JAPAN研究所 & 自然言語処理黒帯
- 研究所とエンジニアの部署で自然言語処理に取り組んでいます。



