こんにちは。サイエンス統括本部でYahoo!ショッピングのレコメンドシステムを開発している山口です。
本記事では、システムの配信ログを大規模データの分散処理が可能な社内のApache Hadoop環境(以下Hadoop)に保存できるように、システム改修した取り組みについて紹介します。
今回改修したレコメンドシステムは、毎秒数千のリクエストを処理する大規模なシステムです。レコメンドシステムから直接Hadoop環境に大量のログを送れるようになったことで、配信情報を素早く、そして簡単にログとして保存できるようになり、日々レコメンドの機械学習モデル改善に役立っています。
Yahoo!ショッピングのレコメンドとは
Yahoo!ショッピングでは、ユーザーが商品のページを見ている時や商品をカートに入れた時などに、ユーザーが興味を持ちそうな関連商品をレコメンド(推薦)して表示しています。ここで関連商品として表示するレコメンド商品を選択し、webページに表示できるように配信するのがレコメンドシステムです。
現在のレコメンドシステムは、表示するページやモジュールに合わせた60種類以上のレコメンドモデルを元にレコメンド商品を返却できるシステムとして、毎秒数千のリクエストを処理しています。
レコメンドの改善と、ログ収集に関する問題
レコメンドシステムが配信するレコメンドは、ユーザーがサービスを利用する中で見た商品やクリックした商品などの情報を元に、日々改善されています。そのようなサービスのログやレコメンドシステムの配信ログは、Hadoopという大規模データを分散処理できる環境に保存されます。
(※データ処理にあたり、ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
元々レコメンドシステムの配信ログは、フロントエンドが実装するログ収集システムによって、レコメンドシステムのレスポンスを通じてサービスのログと合わせて保存されていました。以下がそのシステムの概略図です。
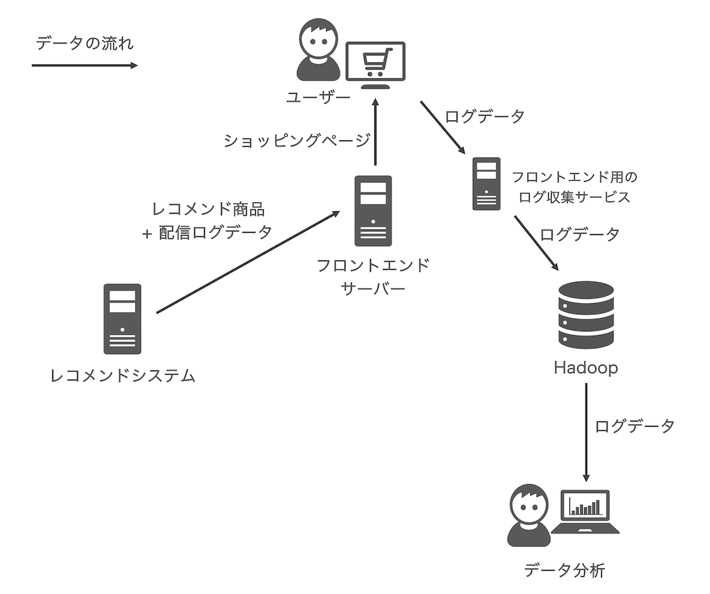
しかし、フロントエンド経由でレコメンドシステムの配信ログを保存するのには、以下のような問題点がありました。
- レコメンドシステムを開発、運用するレコメンドシステムチームがログとして追加で保存したい配信情報が出てきた時、フロントエンドチームと協力をして、レコメンドシステムのレスポンスの変更や、フロントエンド側のログに関する実装に修正が必要となる。
- フロントエンド経由でログが保存されるため、ユーザーの端末はレコメンドシステムの配信ログデータも送受信している。
- レコメンドシステムの配信ログがサービスのログと合わせて保存されるので、レコメンドシステムの配信ログだけを集計するために重いクエリの実行が必要となる。
そこで、レコメンドシステムチームは配信ログとして保存する配信情報の追加や変更をチーム内でのシステム改修で完結できるように、DataLakeの導入を検討しました。
DataLakeの導入
ヤフー社内には、DataLakeという社内プラットフォームがあり、REST APIでデータを受け取り、それをHadoop環境の分散ストレージに保存できます。Apache HadoopはApache Software Foundationによって開発されているソフトウェアフレームワークであり、これを使った社内のHadoop環境では、大規模データを構造化して蓄積し、HiveやPrestoなどのクエリエンジンを通じてデータの集計、分析ができます。そのため、レコメンドシステムは配信ログデータをHTTPリクエストでDataLakeに送るだけで、その配信ログはHadoop環境へ保存され、HiveやPrestoなどのクエリエンジンを使って配信ログの集計ができるようになります。
DataLakeの利用にあたっては、レコメンドシステムが受ける毎秒数千にもなる大量のリクエストに対する配信ログを低い欠損率で保存できるかが重要です。配信ログの欠損は、機械学習モデル改善や、レコメンドの効果の集計などにも影響があります。そこで、レコメンドシステムのDataLake導入は、以下のように段階を踏んで進めていきました。
- DataLake経由での配信ログ保存
既存のフロントエンド経由でレコメンドシステムの配信ログを保存する部分を残したまま、レコメンドシステムからDataLakeへログを送れるようにシステム改修をする。 - 定常集計用クエリコードの修正
定常的に集計しているクエリのコードを、DataLake経由で保存されるレコメンドシステムの配信ログを使って集計するように修正し、問題なく集計できることを確認する。 - レコメンドシステムのレスポンス修正
レコメンドシステムのレスポンスから、フロントエンド経由で保存するためにあった配信ログの情報を削除する。
ここからは、段階的に進めたDataLake導入について詳細を説明していきます。
DataLake経由での配信ログ保存
まずは、レコメンドシステムの配信ログをフロントエンド経由で保存する既存の部分は残したまま、DataLake経由でも配信ログを保存できるようにシステム改修しました。これは、もしシステム改修のバグがリリース後に発覚し、レコメンドシステムの配信ログがDataLake経由で保存できていなかった場合に、フロントエンド経由では配信ログの保存はできているため、配信ログが欠損してしまうという事故を防げるからです。
また、DataLake経由で配信ログを保存するにあたり、レコメンドシステムの配信ログにはレコメンド商品ごとにIDを振りました。レコメンドシステムが良い商品をレコメンドできたか評価する時、レコメンドシステムの配信ログはサービスのログと組み合わせて使われます。例えばABテストをする時、レコメンドシステムの配信ログにあるバケット情報やレコメンドモデル情報と、サービスのログにあるどのレコメンド商品をユーザーがクリックしたのかという情報を使って、どの機械学習モデルで作られたレコメンドがよりクリックされやすいレコメンド商品を選択できているかを集計しています。レコメンドシステムの配信ログをDataLake経由で保存する場合には、レコメンド商品ごとにIDを振り、そのIDをフロントエンド経由で保存するサービスのログに入れることでサービスのログとレコメンドシステムの配信ログを結合できるようにしました。このレコメンド商品ごとに振られたIDは、レコメンドシステムのレスポンスからフロントエンドに伝えられ、サービスのログと共に保存されます。
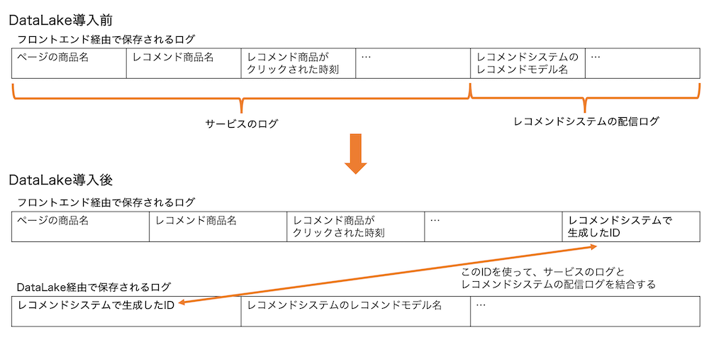
この段階でのレコメンドシステム側の改修は、レコメンドシステムの配信ログとして保存したい情報をDataLakeへ送れるようにすることと、レコメンド商品ごとに振られたIDをレスポンスに含めることの2つです。レコメンドシステムにこの2つの改修をしてリリースし、DataLakeがレコメンドシステムからのリクエストの負荷に耐えられることを確認しました。また、DataLake経由でHadoop環境に保存された配信ログの量を測定したところ、ログの欠損率は許容範囲内でした。
定常集計用クエリコードの修正
続いては、定常的に集計しているクエリコードの修正です。ここでは、改修前のフロントエンド経由で保存された配信ログを使った集計クエリコードを、新しくDataLake経由で保存された配信ログを使った集計クエリコードに変えることで、どれほど集計結果に変化が起きるかを確認しました。
レコメンドシステムを運用する上で、レコメンドシステムチームではレコメンドシステムの配信ログやサービスのログを使って定常的にレコメンドした商品のCTR(クリック率)などの集計をしています。レコメンドする商品を選ぶために使う機械学習モデルを作成するためにも、これらのログは使われます。そのため、レコメンドシステムの配信ログをDataLake経由で保存するように改修する場合、このような集計のクエリコードにも修正が必要です。これらのクエリコードの修正は、レコメンドシステムの配信ログがフロントエンド経由とDataLake経由の両方で保存されるこの期間に行うことで、クエリコード修正による集計結果の違いを見ることができます。2つの方法で保存された配信ログを使った集計結果の違いを確認することで、DataLake経由で配信ログを保存する改修の過程で生まれたバグや、クエリコードの修正でのミスを発見でき、集計結果の違いの定量評価もできます。
新しいクエリコードに問題ないかを確認し、定常集計のクエリコードをDataLake経由で保存された配信ログを使った集計に変更しました。
レコメンドシステムのレスポンス修正
DataLake経由で保存した配信ログが想定通りHadoop環境に蓄積されていることを確認できたので、フロントエンド経由で保存していた配信ログは不要になりました。レコメンドシステムが返すレスポンスから、フロントエンド経由で配信ログを保存するために必要だったフィールドを削除できます。
レコメンドシステムのフロントエンドへのレスポンスは、元々レコメンド商品の情報と、フロントエンド経由でログとして保存するために入れていたレコメンドシステムの配信ログがありました。不要な情報をレスポンスから削除することで、レコメンドシステムのフロントエンドへのレスポンスは、レコメンド商品の情報と、レコメンド商品とレコメンドシステムの配信ログを結合するためのIDのみとシンプルにできます。執筆時点でレコメンドシステムのレスポンスの変更は、フロントエンド側と協力しながら全掲載面への展開に向けて推進しています。
以下がDataLake導入をしたレコメンドシステム改修後の概略図です。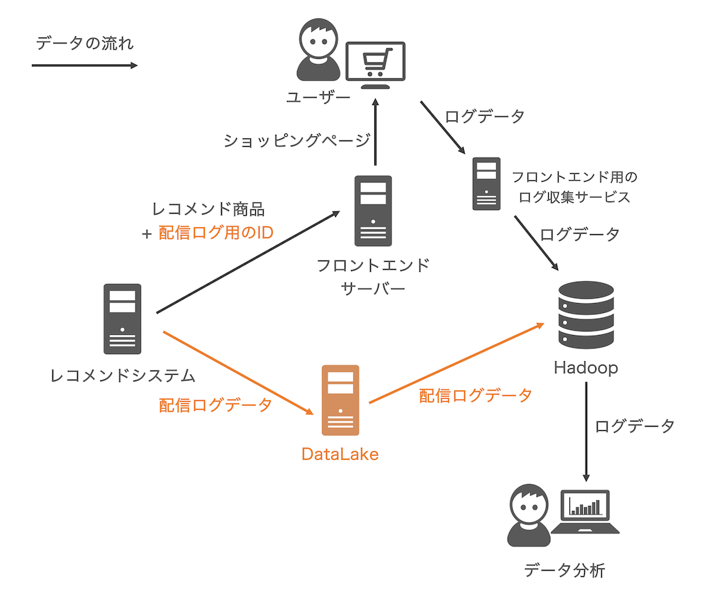
現在のログ活用
DataLake経由でレコメンドシステムの配信ログが保存できるようになったことで、レコメンドシステムチームは保存したいレコメンドシステムの内部情報を簡単にログに追加し、分析できるようになりました。配信ログは独立したテーブルにまとめられ、簡単に集計ができるようになったことで、レコメンドシステムのレコメンド配信状況について分析がしやすくなりました。
また、レコメンドシステムのレスポンスから配信ログの情報を削除したことで、フロントエンド経由で保存されるレコメンドシステムの配信ログ情報はレコメンド商品ごとに振られるIDのみになり、ユーザーの端末はレコメンドシステムのためにそのID以外のデータを送受信する必要がなくなりました。
おわりに
レコメンドシステムは、毎秒数千のリクエストを処理する大規模なシステムであり、システム改修の期間中にログの収集を停止できない中で、段階的に既存のシステムに変更を加えていきました。以前のレコメンドシステムは、レコメンドシステム内部の配信情報をレスポンスに入れてフロントエンドに渡し、フロントエンド側でサービスのログと合わせて保存していました。レコメンドシステムは改修によってDataLake経由で配信ログをHadoop環境に保存できるようになり、新たにログとして必要になったレコメンドシステムの配信情報を、レコメンドシステムチームで自由に配信ログへ追加できるようになりました。また、フロントエンド経由での配信ログ保存がなくなったことで、ユーザーの端末でレコメンドシステムのためにするデータの送受信量を減らせました。
今回は、レコメンドシステムの配信ログに関する改修について紹介しました。今後も私たちは、今回改修したレコメンドシステムと、収集できるようになった配信ログなどを元に、レコメンドシステムを改善しユーザーが使いやすいショッピングの売り場を作っていきたいと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 山口 陽太郎
- 機械学習エンジニア
- Yahoo!ショッピングのレコメンドシステムの開発、運用を担当しています。旅行が好きで、最近登山を始めました。
-



