こんにちは。ヤフーのクラウドプラットフォーム本部に所属している北田、馬場、高橋です。
私たちのチームは社内向けに IaaS 環境を提供しており、その品質を管理・維持するために監視システムを導入しています。
システムの部分的な障害や冗長性などを監視する目的で、私たちはこれまで Sensu を使っていましたが、その EOL をきっかけに Prometheus へ移行することにしました。
この記事では、Sensu の移行先として Prometheus を選んだ理由、Prometheus を利用した監視システムの構成、そして、Prometheus を導入した際の工夫などを紹介します。
ヤフーの IaaS 環境の監視状況
私たちのチームが社内に提供している IaaS 環境では、基盤システムとして OpenStack や Kubernetes を利用しています。
現在運用中の OpenStack クラスタ数は 200 を超え、その上で稼働している仮想マシンは 170,000 台以上です。
また、運用中の物理サーバ数は約 2 万台を超えており、これらの障害対応を迅速に行う目的で、私たちのチームでは障害監視、メトリクス監視、ログ監視などを実施しています。
その中の障害監視について、私たちはこれまで Sensu を利用してきました。
Sensu を利用するにあたり、私たちは 2 つのアラート対応フローを用意しています。
1 つはメール通知、もう 1 つは Slack 通知です。
1 つ目のメール通知は、インシデントの管理や緊急対応が必要なアラートの通知に利用しています。
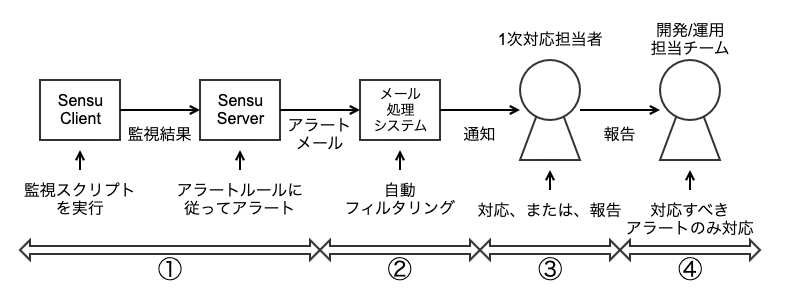
メール通知を利用した対応フローは、以下の図のようになっています。
- Sensu がアラート発火時にメール処理システムにメールを送信します
- メール処理システムがメールをフィルタリングし、対応の必要があるアラートのみを 1 次対応担当者に通知します
- 1 次対応担当者が対応できないアラートの場合は私たち開発/運用担当チームにインシデントを報告します
- 開発/運用担当チームはインシデント報告を受けたアラートのみ対応します
2 つ目の Slack 通知は、インシデントの管理や緊急での対応が必要なく、適当なタイミングで対応すればよいアラートの通知に利用しています。
Slack 通知では、私たちが知りたいアラートを任意のタイミング、任意の通知内容で受け取ることができます。
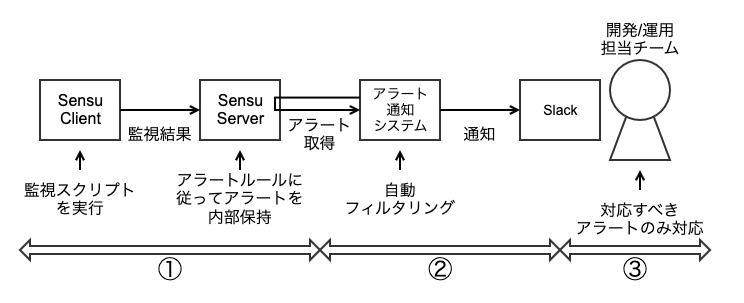
Slack 通知を利用した対応フローは、以下の図のようになっています。
- Sensu がアラート発火時にアラートを内部保持します
- アラート通知システム(内製)が Sensu からアラートを取得し、対応が必要なアラートを Slack に通知します
- 開発/運用担当チームは通知を受けたアラートのみ対応します
また、Sensu は plugin によって監視項目を追加でき、私たちも plugin を独自に用意し、利用しています。
私たちが用意した plugin の総数は 50 を超えており、それらは私たちの資産の 1 つになっています。
例えば、Kubernetes(K8s)の Pod を監視する plugin については、plugin 内で kubectl などのコマンドを実行し、問題のある Pod は復旧を試みつつ、対応が必要な Pod についてアラートをあげる仕組みとしています。
このように、Sensu を使うことで大規模な IaaS 環境を監視してきましたが、Sensu の EOL にあたり次世代の監視システムに移行する必要が出てきたというのが今回の監視システムの移行プロジェクトのきっかけです。
次世代の監視システムの要件と検討
次世代の監視システムの選定にあたり、まずは要件を検討しました。
検討にあたり、過去に Sensu を社内に導入したメンバーとも相談した結果、以下の要件が挙がりました。
- 数万台規模の環境を監視できる
- 現在の Sensu では 2 万台規模のノードの監視を行っており、次世代のシステムでも同等以上の規模の監視が必要
- 性能効率性が良い(リソースあたりの監視可能ノード数が多い)
- スケールアウトができる
- アラート対応フローについて、Sensu 利用時と同様なフローを維持できる
- アラートの 1 次対応を外部へ業務委託しており、アラート対応フローの変更はコストとリスクが高い
- 監視システムに関連するツール、システム、運用体制など監視に関するエコシステム全体への影響が小さいこと
- Sensu で使っていた plugin をそのまま引き継げる
- 監視 plugin の品質は監視システムの品質(障害の検出率など)に直結し、plugin を置き換えた場合のリスクが高い
- 将来にわたって監視システムの品質維持が期待できる
- 多様性をもったコミュニティーで開発や改善が続いている
- システムが広く利用されている
- ドキュメントが整備されている
監視システムの移行によりシステムの品質や可用性を損なうことはあってはならないため、私たちはこの中でも 2 点目と 3 点目を重視しました。
例えば、アラート対応フローの中でシステム運用者が受け取る情報に欠損があると、重要な情報の確認が遅れシステム品質の低下につながりかねません。
また、Sensu で使っていた plugin を引き継げない場合、これまでの運用で改善を重ねてきた plugin を捨て、別の方法で同様な品質の監視を 0 から実現しなければなりません。
以上の要件を踏まえ、既存の監視システムをひととおり検討した結果、Sensu Go と Prometheus が候補に挙がりました。
Sensu Go は Sensu の後継システムとして開発されているので、私たちの求める要件であるアラート対応フローの維持と plugin 互換性が期待できます。
Prometheus は、社内や他社の導入事例からも数万大規模の監視において実績があり、そのナレッジも広く公開されていることから候補に挙がりました。
Sensu Go と Prometheus の詳しい検証結果について、次の章で説明します。
監視システムの検証
Sensu Go
Sensu Go を採用するメリットとしては、監視用 plugin を Sensu からそのまま流用できることに加えて、既存の関連システムとの互換性を保つことが容易なことです。
Sensu Go は、監視対象ノードで Sensu agent が稼働しており、登録したチェック用のスクリプト(監視用 plugin)を定期的に実行して Sensu backend に結果を送信する push 型の監視用ソフトウェアです。この push 型のアーキテクチャは中央の監視サーバに対して監視対象ノードを登録する必要がなく、ヤフーの IaaS 環境のように日々大量のサーバが追加される環境では運用が容易になります。この仕組みは既存の監視システムである Sensu とも変わりはなく、監視に関するエコシステムの多くを既存システムから流用できます。
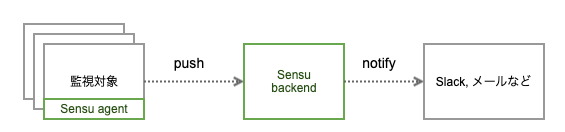
Sensu Go は Sensu の後継システムとして開発されているだけあり、私たちの求める要件である運用フロー維持を容易に満たせます。また監視用 plugin も流用可能であるため、移行後の監視品質もある程度は担保できます。Sensu Go は現在も開発が続けられており、ドキュメントも充実しています。
監視システムに求められる要件でも触れたように、私たちの監視システムでは 2 万台以上のノードを監視する必要があります。
そこで従来のSensuに利用していたサーバと同程度の性能の8vCPU, 16GB の RAM の仮想マシンを利用し性能検証を行いました。
はじめに単一の Sensu Go サーバで性能検証を行い、実際に多くの監視対象ノードを徐々に追加して、稼働しているサーバのメトリクスを確認します。
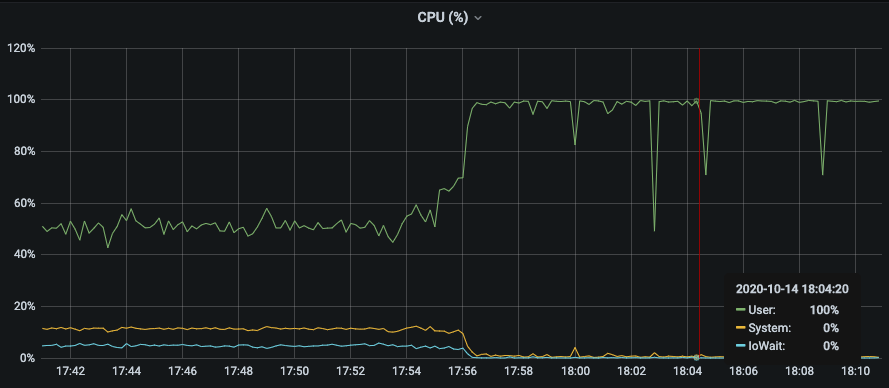
上記の図は単一の Sensu backend に対して 9000 台の監視対象ノードを追加したときのサーバの CPU 使用率です。
CPU の使用率が 100%付近と高く、監視対象ノードの台数に対して処理能力が追いついていないように見えます。
Sensu Go は etcd を共有ストレージとしたクラスタを組むことができ、監視システムのキャパシティをスケールアウトさせることが可能です。そこで、クラスタを組んだ状態でも性能検証を行うことにしました。以下は、クラスタを組んだ状態で単一の Sensu backend での検証と同じく 9000 台のクライアントを追加したときのサーバの CPU 使用率です。
仮想マシンはクラスタを組む前と同じ性能のものを 3 台使用しています。
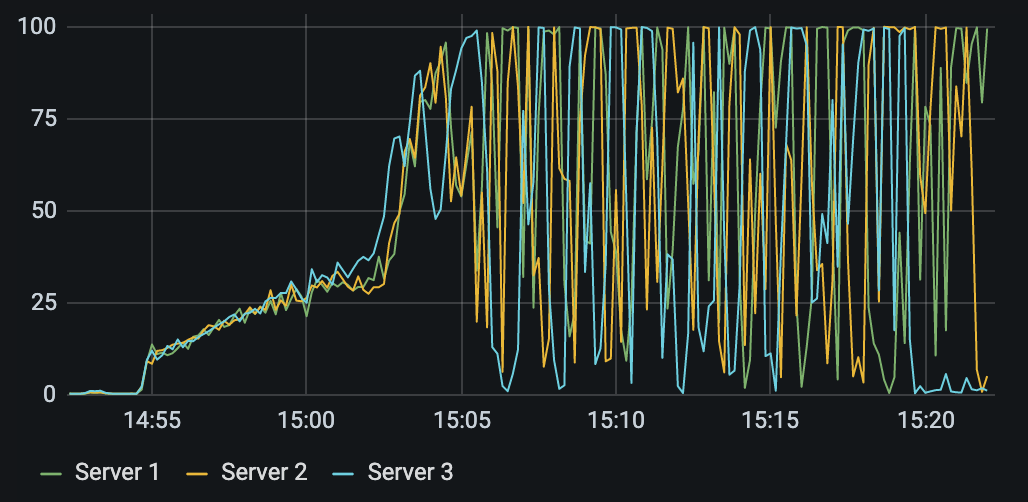
9000 台追加後は単一構成よりは CPU 使用率は低くなっていましたが、アラートなどを取得するために API にアクセスした際に CPU 使用率が非常に高くなり動作が不安定になってしまいました。
Prometheus
次に検討したのは Prometheus を用いた監視システムです。Prometheus は Sensu とは対象的に Prometheus server が能動的に監視対象ノードのメトリクスを収集をする pull 型の監視用ソフトウェアです。
Prometheus を利用した基本的な構成は以下のようになります。
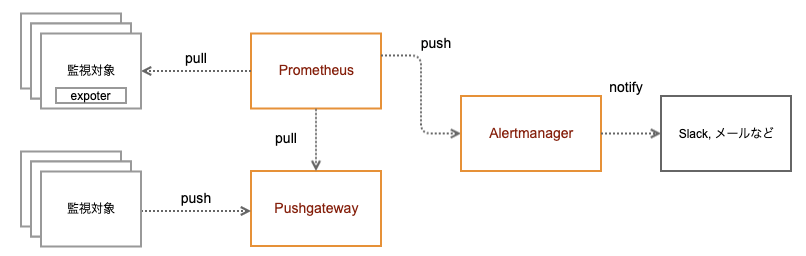
- Prometheus
- あらかじめ設定した監視対象ノードの exporter が公開しているメトリクス情報を取得します
- 内部に持つデータベースに収集したメトリクスデータを一定期間保持します
- あらかじめ設定したアラートルールにのっとって、メトリクスの値がしきい値を超えた場合に、Alertmanager にアラートを通知します
- Alertmanager
- Prometheus から受信したアラートをメールや Slack などで通知します
- 受信したアラートのうち特定のホストやラベルを持ったものは通知しないように抑制する機能もあります
- Pushgateway
- 通常は Prometheus は監視対象ノードに対してメトリクスの収集をする pull 型のアーキテクチャですが、その逆の push 型の対象を組み込みたいときには Pushgateway を経由して収集を行います
- Prometheus は Pushgateway からメトリクスを収集することで、 Prometheus のアーキテクチャを変更することなく、監視対象ノードからのメトリクスの push を実現できます
Prometheus は数万大規模の監視という面では社内や他社の導入事例からも実績のあるソフトウェアです。
しかし任意のスクリプトを監視として組み込む自由度という面では Sensu に劣ります。Prometheus はメトリクス監視に特化した監視システムです。そのため exporter で公開するまでの、任意のスクリプトをクライアントに定期的に実行させるための仕組みは自前で用意する必要があります。また時系列データとして扱えるスクリプトのステータスコードなどに関しては問題ありませんが、スクリプトの出力結果の保持は難しいです。私たちの監視フローではスクリプトの出力結果に応じたフィルタリングを行っていたり、スクリプトの出力結果の推移を頼りにアラートの根本原因を調査することもあります。
そのため、運用フローを変更せずに Prometheus を私たちの環境に導入するためには、ある程度足りない機能は自分たちで実装し補完しなければなりません。
続いて性能の観点から Prometheus を見てみます。
参考に Prometheus を Kubernetes(K8s)上にデプロイして性能検証を行った際のデータを示します。
以下は監視対象ノードを 1 台も追加していない状態の Prometheus Pod の CPU 使用状況です。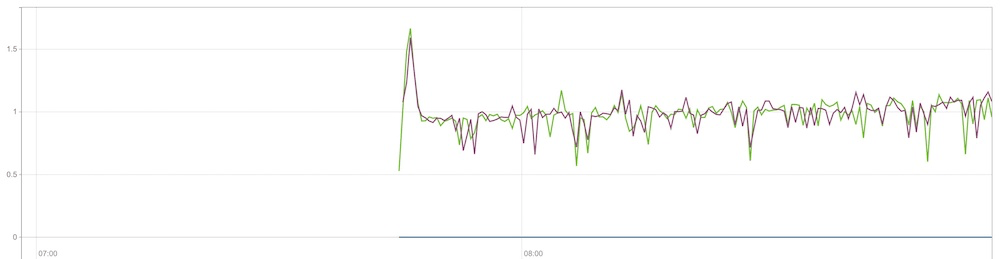
縦軸は K8s における CPU 数の消費量を示していて、その値は私たちが K8s のノードとして利用しているサーバの CPU コア数 (おおよそ 80〜) に比べてとても少ないことがわかります。
それに対して以下は 1 万台の監視対象ノードを追加した状態です。
1 万台追加後は何も追加していない状態に比べわずかに CPU 使用量が増加していますが、急激な上昇は見られませんでした。
また、CPU 以外のリソース使用量に関してもわずかな上昇しかありませんでした。
そして、API やアラートの通知など基本的な機能はもたつくことなく動作しており、この規模の監視であれば十分に機能させられることがわかりました。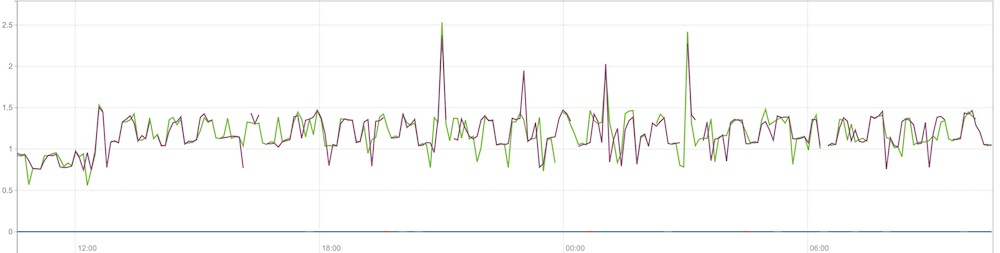
検証結果
掲載した CPU リソースの消費以外にもメモリやディスクの消費や負荷というさまざまな観点で性能検証を行いました。結果 Prometheusは Sensu Go と比較してリソース消費量に対して多くの対象を監視できることがわかりました。そしてリソース消費量の観点に加え社内での利用実績を考慮したところ、最終的に Prometheus のほうが私たちの要件を満たせるだろうという結論に至りました。
しかし、Prometheus は監視系ソフトウェアの中でも時系列メトリクスを扱うソフトウェアであるため、私たちの運用フローに落とし込むためには、いくつかの追加実装が必要です。
次の章では、Prometheus を私たちの要件に合う監視システムとして稼働させるために必要だった変更点・工夫した点についてお話しします。
コラム: 社内の監視サービスは利用しないの?
ヤフーでは社内の各サービスが個別に監視システムを構築する手間を省き、高い品質の監視を実現するために社内向けに SaaS で監視システムを提供しています。
通常であればサーバやサービスの監視にはこの SaaS を利用するのが社内では一般的です。
しかし私たちの IaaS のような大規模な環境の収容が難しいことに加えて、そもそもこの SaaS で提供される監視サービスも IaaS を利用してサービス提供しているため、IaaS で障害が発生すると監視サービスにも影響が及び IaaS の障害を検知できなくなるという問題があるため IaaS チームでは監視システムを独自に構築しています。
システムの全体構成
Prometheus を採用した新しい監視システムの全体構成を説明します。
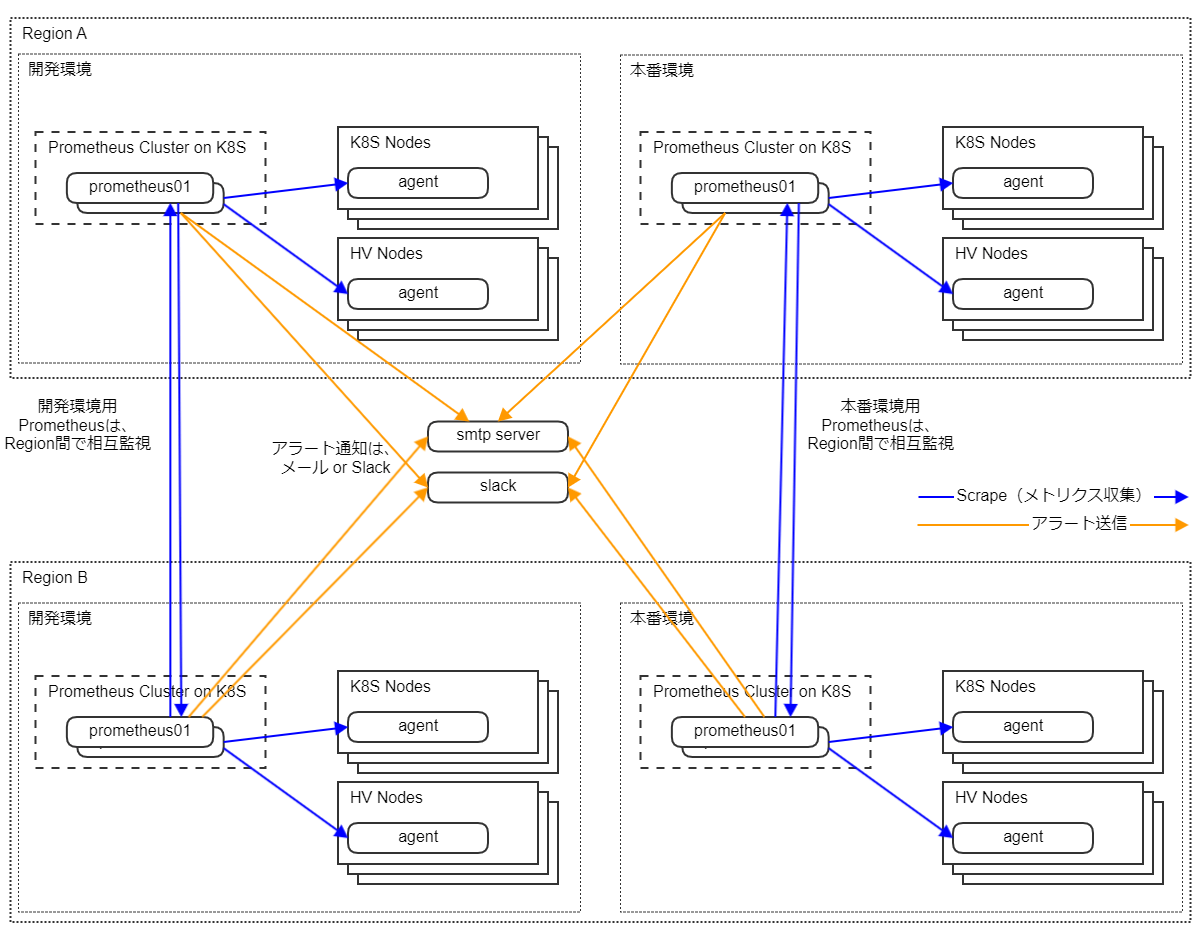
まず、私たちの監視対象は IaaS を構成する全てのサーバ/システム群であり、これには K8s のノードや、OpenStack の HV ノードが含まれます。
これらは開発環境用と本番環境用で分かれており、またその設置場所もリージョンを東西に分けて配置されています。
これに合わせて、Prometheus クラスタ(2 台 1 組の Prometheus と Alertmanager などのセットのこと)も各環境用、リージョン用で分けてシステムを構築しました。
このように Prometheus クラスタを分ける理由は、冗長性の確保およびスケールアウトの実現のためです。
Prometheus 自体にはクラスタリングといった機能はなく、冗長化はできず、そのシステム性能はマシン性能に依存します。
そこで、冗長化のために 2 台の Prometheus に同じ設定を行い、多重化することで冗長性を担保しています。
また、 Prometheus 単体の性能はスケールできないため、Prometheus クラスタを環境ごとに用意して、1 つのクラスタの扱うノード数・メトリクス数が一定規模で収まるようにシステムを構成しました。
コラム: federation はする・しない?
Prometheus には複数の Prometheus のメトリクスを別の Prometheus で収集しなおして中央管理できる federation の機能がありますが、これは以下の理由から利用していません。
- メトリクスの評価とアラート発火を中央管理の Prometheus で行うとアラートの検知が遅れる
- 後述する内製の Web UI によって統合されたメトリクス/アラートの参照および操作ができるため、わざわざ federation をするメリットがない
- 中央管理の Prometheus はスケールアウトさせることはできないため、federation に頼った構成はスケール性の観点で懸念がある
コラム: Web UI
上述のコラムで fedreation はしないと説明しましたが、これには実は 1 つ問題があります。
Prometheus や Alertmanager が複数あると運用者はそれらすべての UI を閲覧する必要があり、これはとても不便です。
そこで、私たちは専用の Web UI を内製し、各 Prometheus、Alertmanager を横断して、ノードやアラートの一覧表示・詳細表示、またサイレンスの一覧表示やサイレンスの操作ができるようにしています。
Prometheus クラスタの詳細構成
次に、Prometheus クラスタの詳細構成を説明します。
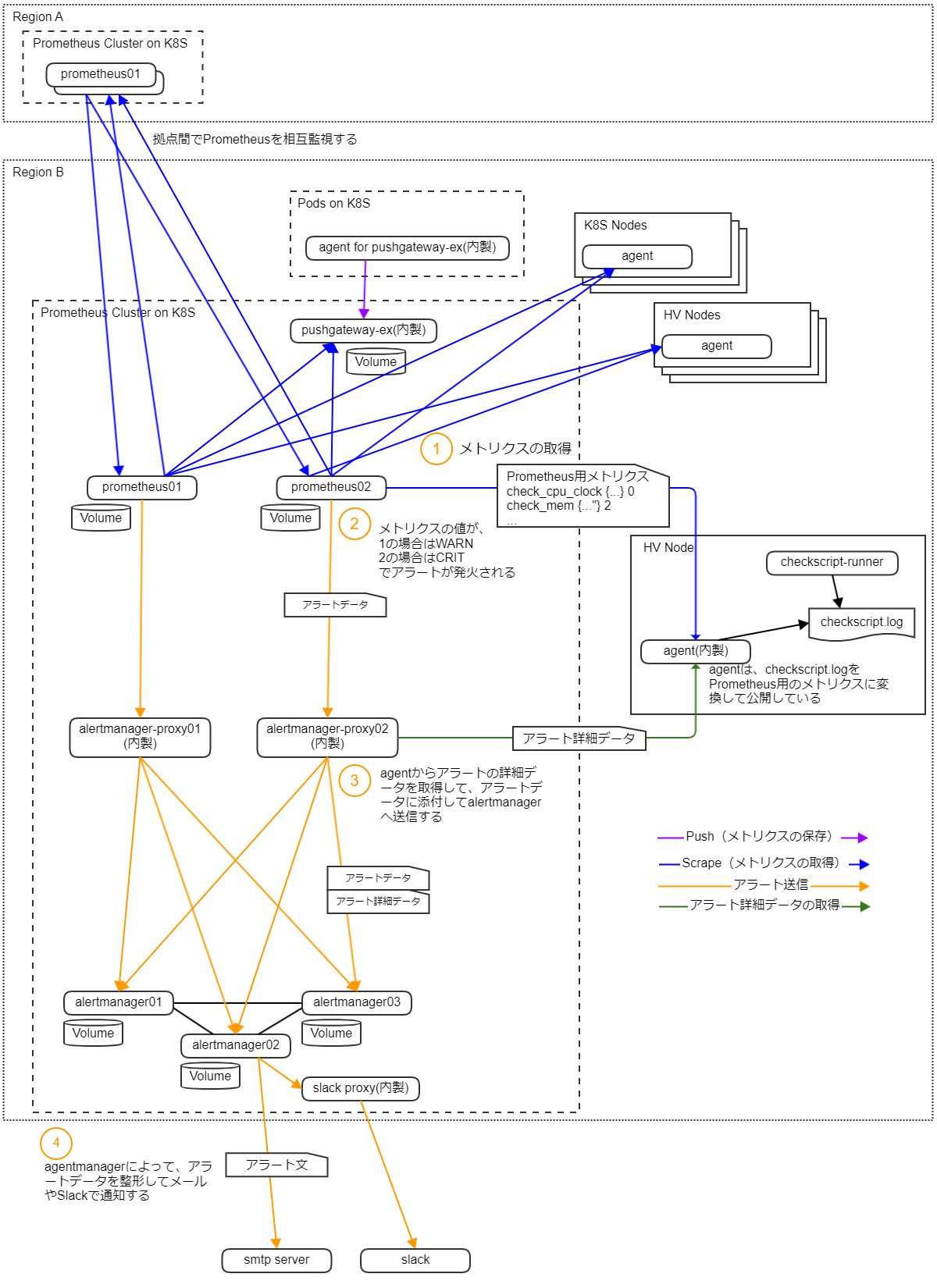
まず、Prometheus は同じ設定のものが 2 台 1 組で稼働しており、これらは全く同じノード群からメトリクスを収集し、監視しています。
この Prometheus は K8s 上で稼働しており、プロセスがダウンした場合は K8s のオーケストレーション機能によって自動で再起動して復旧します。
またデータの永続化のために Persistent Volume を利用しています。
アラート発生までの流れは以下のようになります。
- メトリクスの取得
- Prometheus は、監視対象ノードから定期的にメトリクスを取得しています
- メトリクスの評価とアラート発火
- Prometheus は、一定周期でメトリクスを評価しており、アラートルールに引っかかった場合にアラートを発火します
- 私たちのアラートルールではメトリクスの値が 1 なら WARN、2 なら CRIT としてアラートを発火させています
- アラートデータに詳細データを添付する
- Prometheus のアラートデータには対象ノードのデータとメトリクスとしての数値データしか含まれないため、スクリプトの標準出力などアラートの詳細データを監視対象ノードから取得して、これをアラートデータに添付します
- alertmanager によって、アラートデータを整形し、従来通り(Sensu と同等)のアラート文をメールや Slack で通知します
ここで Prometheus をご存じの方は、一般的な利用方法とは少し異なっていると感じられたかもしれません。
私たちの構成では、いくつかの目標を達成するために一般的な構成とは少し異なる構成・使い方をしています。
以下では、その利用方法の違いにフォーカスして、私たちの Prometheus クラスタをもう少し詳しく説明します。
メトリクスの収集・アラート評価の仕組みの違い
一般的な Prometheus の仕組み
- 監視対象ノードは単純なリソースの利用状況などをメトリクスとして公開します
- Prometheus は監視対象ノードからメトリクスを定期的に収集し、別の周期で定期的にアラートルールをもとにメトリクスを評価して、アラートを発生させます
IaaS チームでの Prometheus の仕組み
- 監視対象ノードでは、sensu-client 互換のチェックスクリプト実行用の agent(checkscript-runner)が稼働しており、スクリプトの実行結果をログとして出力しています
- 現在は sensu と Prometheus の並行稼働期間なので、この checkscript-runner には sensu-client を利用しています
- 並行稼働期間内に、開発環境から順次 sensu-client を 内製の checkscript-runner に置き換えてゆき、最終的には sensu-client の利用をやめる予定です
- 監視対象ノードでは、上記の checkscript-runner(もしくは sensu-client)とは別に独自の agent が稼働しており、この agent が checkscript-runner の実行ログをパースして Prometheus 用のメトリクスとして公開しています
- sensu ではチェックスクリプトの結果が正常なら 0、WARN なら 1、CRIT なら 2 で表現しているため、メトリクスもその値をそのまま利用して公開しています
- Prometheus は監視対象ノードからメトリクスを定期的に収集し、アラートルールをもとにメトリクス評価して、アラートを発生させます
- 一般的な利用方法との違いとしては、Prometheus は Sensu 相当のチェック結果をそのまま評価して、アラートを発生させています
- メトリクスを評価するという点は一般的な使い方と変わらないですが、その評価内容は、1 なら WARN、2 なら CRIT でアラートを発生させるという単純なルールだけが存在します
この仕組みのメリット・デメリット
- メリット
- メトリクス数・評価コストの削減
- チェックをノード側で行い、その結果が 1 つのメトリクスとなるので、メトリクスの項目数を大幅に削減できます
- 例えば、メモリ利用の監視では、チェックスクリプトで /proc/vmstat を参照して、そのチェック結果が 1 つのメトリクスとして公開されます
- 一方で、一般的な方法で監視しようとすると、/proc/vmstat 内の主要な値をすべて別々のメトリクスとして扱って公開する必要があり、メトリクスの量も肥大化し評価のための計算コストも増えます
- チェックスクリプトの自由度が高い
- 一般的な Prometheus では、監視したいものすべてをメトリクスに落とし込む必要があります
- 例)ログ、コマンドの出力結果など
- チェックスクリプトで監視する場合は、メトリクスに落とし込みずらいものも容易に監視できます
- 一般的な Prometheus では、監視したいものすべてをメトリクスに落とし込む必要があります
- メトリクス数・評価コストの削減
- デメリット
- 新規の監視設定の追加が大変
- チェックをノード側で行うため、新規の監視を追加する際には新しいチェックスクリプトを全ノードに配置する必要があります
- 一般的な方法であればメトリクスとしてさまざまなリソースの利用データを Prometheus が保持しているため、Prometheus 側に新しいルールを追加するだけですみます
- もちろん監視したいものが現在扱っていないメトリクスであれば、新たにそれを収集するために全ノードに設定を行う必要があります
- 新規の監視設定の追加が大変
アラート発生後の仕組みの違い
一般的な Prometheus の仕組み
- Prometheus はアラートが発生した場合は、これを Alertmanager へ転送します
- Alertmanager は設定に従ってメールなどで運用者に通知を行います
IaaS チームでの Prometheus の仕組み
- Prometheus はアラートが発生した場合は、これを alertmanager-proxy(内製)へ転送します
- alertmanager-proxy は、アラートを受信したら監視対象ノードからアラートの詳細データを取得し、アラートデータに埋め込み、Alertmanager へ転送します
- 詳細データを取得できない場合は、その旨をアラートデータに埋め込みます
- Alertmanager は設定に従ってメールなどで運用者に通知を行います
この仕組みのメリット・デメリット
- メリット
- アラートデータにその詳細データを埋め込める
- ここでいうアラートの詳細データというのは、例えばメモリ監視であれば/proc/vmstat の中身といった文字列データです
- 一般的な利用方法では、Prometheus から Alertmanager へ直接アラートを渡すため、また Prometheus では文字列データを扱えないため、アラートのデータは簡素なものとなります
- 補足として、アラートデータの annotations に簡単な文字列データ(Prometheus の持っている情報から出力できるものに限る)を埋め込むことはできます
- アラート文に、詳細データを添付すべきかについては議論の余地がありますが、私たちは必要と判断しました
- もともと利用していた Sensu でもチェック結果の標準出力といった情報はアラート文に記載しており、その運用のなごりもあります
- これは、既存の運用フローに影響を与えないよう最終的な通知内容の互換性を保つためです
- アラートデータにその詳細データを埋め込める
- デメリット
- 特になし
内製したもの紹介
簡単にですが、今回のシステム構成にするにあたって内製したものを紹介します。
これまでの説明や図にないものもありますがご了承ください。
- checkscript-runner
- sensu-client のチェックスクリプト実行用の agent です
- チェックスクリプトの実行結果を sensu-client と同等のフォーマットでログ出力します
- agent
- いわゆる exporter です
- チェックスクリプトの実行ログを Prometheus のメトリクスとして公開します
- また、単純なメトリクスだけでなく、チェックの詳細結果も取得できます
- pushgateway-ex
- 注意)名前が紛らわしいですが、公で提供されているものではありません(ですが役割は同じです)
- 内製した理由としては、通常の Pushgateway の機能に加えてチェックの詳細結果を保存し、取得できるようにするためです
- agent for pushgateway
- そのままですが、pushgateway 用の agent です
- チェックスクリプトを定期実行し、その結果を pushgateway に push します
- Alertmanager proxy
- Prometheus から送られてきたアラートデータに、agent から取得した詳細結果を添付して、Alertmanager へ中継します
- web ui
- Sensu でいうところの Uchiwa のようなダッシュボードです
- Uchiwa: Sensu におけるノードやアラートの状態を確認するための web ui です
- 複数の Prometheus クラスタを横断して、ノードやアラートの一覧表示・詳細表示、またサイレンスの一覧表示やサイレンスの操作ができます
- Sensu でいうところの Uchiwa のようなダッシュボードです
コラム: Prometheus on K8s は大丈夫?
私たちの Prometheus クラスタは K8s の上で稼働しています。
しかし、その基盤となる K8s の監視はその上で稼働している Prometheus が行っています。
もし K8s で障害が発生した場合、Prometheus も正常に動作できず K8s の障害に気づけなくなります。こういった事態に備えて IaaS チームでは 複数の K8s を異なるリージョンに用意し、相互監視を行っています。
Prometheus クラスタが 1 つだけであれば、K8s が完全にダウンすると、その上の Prometheus クラスタも停止するので、アラート通知も飛ばずに運用者は気づけません。
しかし、別リージョンの Prometheus クラスタと相互に監視を行っているので、もう一方のリージョンの Prometheus がアラート通知を行ってくれるので運用者はこれに気づけます。
あとは、運用者が頑張って K8s を復旧させるだけです。
つまり、K8s が完全にダウンするとその環境の監視は全て停止してしまいますが、運用者がそれに気づけないという最悪の事態は回避できる構成になっています。
コラム: ラベルの間違った使い方
Prometheus にチェックスクリプトの標準出力といった文字列データを入れたいと思ったときに、最初に行ったのがメトリクスのラベルに文字列データを埋め込むということでした。
しかし、Prometheus ではラベルによってメトリクスの唯一性を担保するので、ラベルの中身が変化すると同じノードからの同名のメトリクスであったとしても、それは別物として扱われてしまいます。
このため、動的な文字列データをラベルに仕込むと、メトリクス量が肥大化し、またメトリクスの評価も単発では一応動作するが、一定期間での評価はできなくなってしまいました。
結論としては、ラベルにコマンドの出力といった実行のたびに変化するような文字列データを入れてはいけませんでした。
まとめ
本稿では、Sensu の EOL をきっかけに次期監視システムの検討を行い、実際に導入したシステムについて紹介しました。
本来であれば、新しい監視システムの導入にあたりシステムの運用フローもその監視システムにあったものに変えていくのが理想と言えます。
しかし、数万台のノードから構成されるような大規模な IaaS システムを監視する場合は、運用フローに手を加えるよりも監視システムを運用に合わせてカスタマイズした方がコストが少なく、移行に際してのリスクも小さいと判断して今回のようなシステムを構築しました。
また、ヤフーの IaaS チームは開発と運用が一体となっており、監視システムの要件を熟知した運用エンジニアが、今回のような監視システムのカスタマイズできるスキルを持っていたことも今回のような選択をした大きな要因となっています。
とはいえ、運用フローの維持はあくまでもシステムの品質を高く保つために今回とった手段であって本来の目的ではないため、今後は Prometheus 本来の使い方に合わせて運用フローも変えるべきところは変え、柔軟に改善を続けていきたいと考えています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 北田 駿也
- インフラエンジニア
- 2013年入社、OpenStack、Kubernetes、監視システム、Web UI、ソフトウェアロードバランサなどの開発・運用を担当しています。
- 馬場 隆彰
- インフラエンジニア
- 2017年に入社し、Kubernetes、OpenStack、ストレージ、監視システムなどの構築、運用を担当しています。
- 高橋 陽太
- インフラエンジニア
- 2020年入社以来IaaSチームにてOpenStackやKubernetesおよびその関連システムの開発運用に従事しています。



