こんにちは。データソリューション本部データフィケーション技術部の関根剛宏です。
今日は私たちが取り組んでいるデータフィケーションについてお話したいと思います。
データフィケーションとは
データとはもともと「与えられたもの」という意味があります。コンピューターが誕生する前から人間は生活の営みの中で文字や数値を記録するという行為を行ってきました。距離の測量、貨幣の計算、天気や天体などの自然現象の観察、人や物の数え上げなどを行い、それらを記録しデータ化すること、またそのデータを整理し、分類することで日常生活や商業生活をより効率的、合理的に営むことを可能にしました。またこれらのデータを「与えられたもの」として表にまとめたり、グラフにして推移を見たり比べて、再利用したり法則や傾向を見い出し有用な判断や価値を見つける、といった行為は古来行われていました。

近年、ハードウエア能力の向上により、数値やテキスト、音声、画像といった世の中のさまざまな情報をデータベースに格納できるようになりました。そうして集めた大量の情報はビッグデータと呼ばれ、そこからさまざまな価値を抜き出すことに注目が集まっています
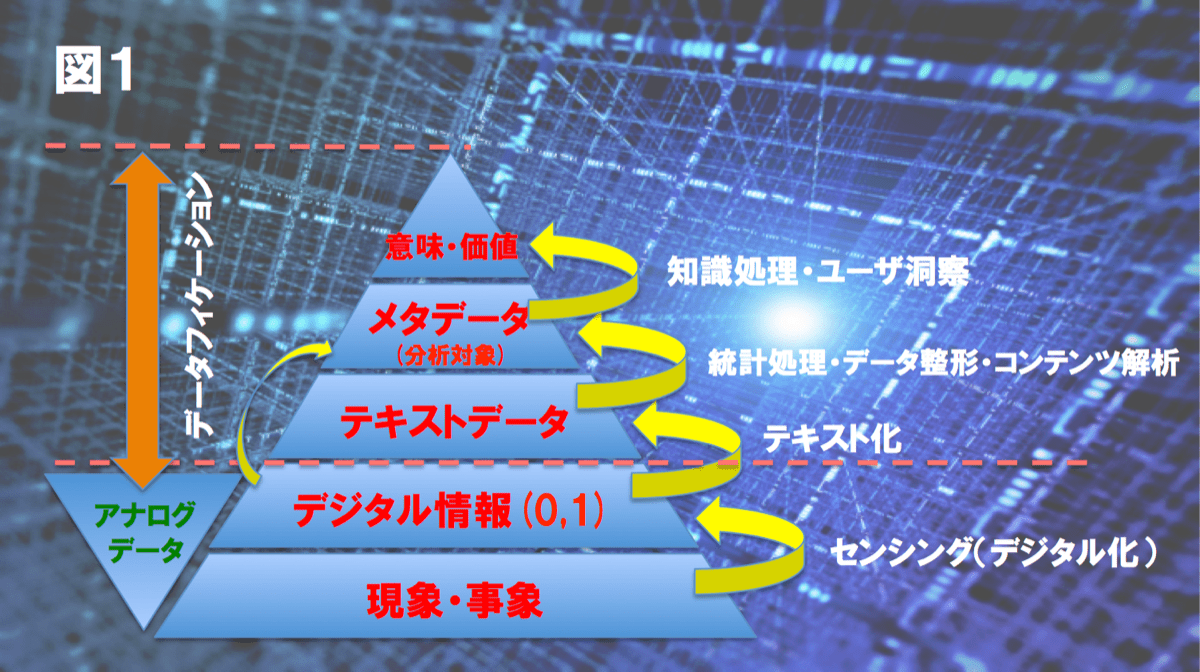
データフィケーションは、日本語では直訳すると「データ化すること」という意味です。音声や画像は、センシングによりデジタル化されていますが、それだけでは価値を取り出すことは容易でありません。
一方、音声認識やOCRを通して音声や画像をテキストデータに変換することで、特定の言葉が含まれているかを探すなど簡単な集計・分析ができるようになります。さらに高度な収集・分析のためには、生のテキストデータを扱うよりも、テキストにどのような内容が記載されているかを表すメタデータを使うほうが効率的です。
このように「データフィケーション」とは、デジタル化をさらに押し進めた概念で、デジタル情報を集計・分析が可能な状態にすることを意味し、そのためには、
・デジタル化した情報をテキストデータに変換すること
・テキストデータからさまざまなメタデータを抽出すること
が必要になるとわれわれは考えています。(図1参照)
データフィケーションと非構造データ
一般的に非構造データは画像や動画、音声、Twitter、Facebookやブログへの書き込みなどRDBに格納されていないデータを指すことが多いと思います。ビッグデータという文脈の中では非構造データの扱いの重要性についての説明を目にすることがありますが、この分野のプレーヤー企業のスタンスとしてはPaaSや分析ツール(※1)を提供する所が多いようです。
ヤフージャパンでは生のコンテンツデータから属性や意味的な情報を抽出して活用したいというニーズをさまざまなヤフーのサービスにおいて捉えていますので、そのニーズに合わせて必要となる最適なインフラを構築したり、構造化対象を明確にして適切にモデリングしデータ化するといった事やデジタル化された情報を分析可能な状態に変換することを重要視しています。
非構造データの活用(画像)
例を挙げると、グルメに関するサービスで大量のユーザー投稿画像のなかから美味しそうな料理の画像だけを自動抽出して提示すれば、よりユーザーの興味を引きサイトの魅力を上げるという事もできそうです。
ここで「美味しそうな料理の画像」というのは主観的な表現ですが、人間の感覚と相関を持つ一定量の料理画像データを(プライバシーポリシーに従って)用意し、Deep Convolutional Neural Networkの技術を用いて教師あり(または教師なし)学習を行い、自動分類(ラベル付け)する仕組みを構築することで有用なレコメンドなどを実現できそうです。
このような例は多量のデータが集まり、豊富な計算資源を持つヤフージャパンならでは実現できるデータフィケーションと考えています。
非構造データの活用(音声)
また別の非構造データ活用の代表的なものとして音声認識があります。スマートフォンに発声した音声をサーバーへ送りサーバーで音声を認識し、認識結果をクライアントに返す分散音声認識は多くのスマートフォンアプリで一般的に利用されています。発話の内容はアプリケーションに依存してさまざまな形態がありますが、WEB検索のように単語ベースの発話をする形式と「音声アシスト」のようにエージェントに話しかけて対話的な発話をする形式などが代表的です。
対話的な発話は単語ベースと比べ文章的な内容になる傾向がありますので、単に認識結果をテキストとして変換できたとしても、構造化されたとは言いにくいでしょう。そこで、認識されたテキストを形態素解析(※2)に掛けることにより、より構造的なデータに近づけることができます。ヤフージャパンではスマートフォンのさまざまな利用環境、さまざまな発話音声に対して認識ができる日本語音声認識プラットフォーム(※3)を開発しました。認識エンジンはヤフージャパン独自のもので大語彙の認識が精度良くリアルタイムでできることが特徴です。
また音声情報からはその人の性別や年代といった属性情報を抽出することもある程度可能です。
このような属性情報を音声認識の認識結果と組み合わせれば、ユーザーに属性情報の入力を強いることなく「どのようなユーザーがいつどのような興味関心を持ったか」ということを分析しやすくなります。そのようなユーザーの興味関心が広告であれば広告マーケティング、商品であれば製品マーケティング、というようにデータフィケーションの技術はマーケティングへの応用にもつなげることができると言えるのではないでしょうか。
非構造データの活用(テキストデータ)
テキストデータをより使いやすくする技術として、コンテンツ解析があります。
コンテンツ解析を使うことで、テキストデータに対してさまざまなメタデータをつけることができます。
例えば、「仙台に居酒屋「塚田農場」-宮崎の地鶏や郷土料理を提供 /宮城」というニュースが「宮城県仙台市」に関して書かれていることがわかれば、ユーザーが現在いる場所近くのニュースを提供するといったことが可能になります。このように、ニューステキストに対して、そのニュースがどの地域に関して書かれたものかという情報がメタデータです。
別の例として、「東海テレビ・フジテレビ系の昼ドラマ「白と黒」で主演を務めた西原亜希が、第1子となる女児を出産したことを発表した。」というニュースが、「白と黒」や「西原亜希」に関してということがわかれば、ユーザーにそのドラマのあらすじや、その女優の他の出演作品をあわせて情報提供することが可能になります。このような、作品や人名といった情報もメタデータになります。
このように、コンテンツ解析によってメタデータを機械的に付与することで、生のテキストデータでは難しかった、さまざまな活用が可能になります。
データフィケーションとマルチメディア
私たちは大量の非構造データに埋まっている価値は莫大なものであると考えています。
しかしながら非構造データを構造化データに変換することは一般的に実現難易度が高く、さまざまな技術的課題を解決しなければなりません。
私たちはまず音声、画像、映像のデータ(これらをマルチメディアデータと定義しています)にフォーカスし、これらのデータの構造化にチャレンジしています。音声であれば高精度な音声認識、話者属性推定、画像や映像であれば画像認識、一般物体認識、映像理解、動画字幕付け等々多岐に渡る技術とプロダクトの開発を行っていて、これらの技術一つ一つはデータフィケーションを実現する要素と言えるでしょう。
最近では深層学習をはじめ脳神経科学の知見も参考にしながら、マルチメディア処理プロダクトを開発し、将来的には人間と同じ程度(またはそれ以上)の認知能力を備えたデータフィケーションの進化を追求して行きたいと思っています。マルチメディアデータとサイエンス、コンピューティング環境の全ての力を併せたとき、新しい価値創出が実現していくことでしょう。
あなたも私たちと一緒にデータフィケーションとマルチメディア技術の先駆者としてヤフーで活躍してみませんか?(採用情報はこちら)
(※1) SAS Visual Analytics, IBM InfoSphereなど
(※2) 文章を意味を持つ最小の単位で区切り品詞情報などを付与する解析器
(※3) YJVOICEで商標登録
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



