こんにちは、地域サービス事業部の吉田一星です。
今回は、Hadoopについて、Yahoo! JAPANでの実際の使用例を交えながら書きたいと思います。Hadoopとは、大量のデータを手軽に複数のマシンに分散して処理できるオープンソースのプラットフォームです。
複数のマシンへの分散処理は、プロセス間通信や、障害時への対応などを考えなければならず、プログラマにとって敷居が高いものですが、
Hadoopはそういった面倒くさい分散処理を一手に引き受けてくれます。
1台では処理にかなり時間がかかるような大量のデータも、複数マシンに分散させることで、驚くべきスピードで処理を行うことができます。
例えば、今まで1台でやっていた、あるログ集計処理を、Hadoop(マスタ1台、スレーブ19台)で行うようにしたところ、
| Hadoop | 5分34秒 |
|---|---|
| 従来の処理 | 6時間6分35秒 |
集計処理のやり方が違うので単純比較はできませんが、Hadoopの威力がおわかりいただけるかと思います。
もちろん、サーバの台数をもっと増やせば、それだけ処理能力は向上しますが、数GB程度のデータ処理ならば、数台でも十分に効果を実感できるのではないでしょうか。
MapReduce
Hadoopを説明する上で、避けては通れないMapReduceについて説明します。
MapReduceは、Hadoopで用いられるプログラミングモデルで、Googleの論文が元になっています。
ユーザはMap関数とReduce関数を用意するだけで、あとはHadoopが勝手に複数のサーバで分散処理をしてくれます。
Mapは入力データを読み込みフィルタリングする役割、ReduceはMapから渡されたデータをまとめ上げて結果を出力する役割をします。
Map、Reduceはそれぞれ独立して多数のサーバに分散して処理されます。
例えば、あるテキストの中で出現する単語をカウントする処理(WordCount)を考えてみましょう。
THE END OF MONEY IS THE END OF LOVE
というテキストがあったとすると、各単語の出現数は、
| THE | END | OF | MONEY | IS | LOVE |
|---|---|---|---|---|---|
| 2 | 2 | 2 | 1 | 1 | 1 |
ですが、これをMapReduceで処理してみます。
Map
Mapは、「THE END OF MONEY IS THE END OF LOVE」というテキストを入力として読み込みます。
そして、それぞれの単語に「1」という値を割り当てます。
| THE | END | OF | MONEY | IS | THE | END | OF | LOVE |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
MapReduceのデータは、KeyとValueのペアで表されます。
Key、Valueのペアを<Key,Value>と表せば、Map処理は、入力テキストから次のような<Key,Value>を作り出すことです。

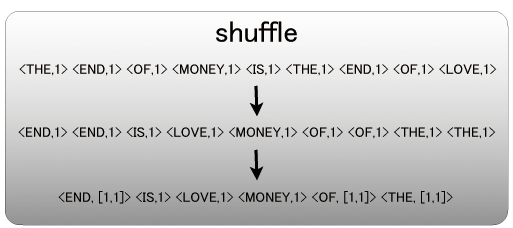
Shuffle
Mapの出力をキー順にソートし、同じKeyをもつペアを束ねるのがShuffleです。(オプションで数値順にソートなども指定可能)
キー順にソートすることにより、同じKeyをもつペア同士が隣り合います。
そして、隣り合った同じKeyをもつペアは、束ねられます。
Shuffleは、MapからReduceにデータを渡す際に自動的に行われます。
- 入力
THE END OF MONEY IS THE END OF LOVE 1 1 1 1 1 1 1 1 1 - キー順にソート
END END IS LOVE MONEY OF OF THE THE 1 1 1 1 1 1 1 1 1 - 同じKeyを束ねる
END IS LOVE MONEY OF THE 1 1 1 1 1 1 1 1 1
Reduce
Shuffleの結果を入力として処理を行います。
WordCountでは、同じKeyのValueを足し合わせます。
- 入力
END IS LOVE MONEY OF THE 1 1 1 1 1 1 1 1 1 - Reduce後
END IS LOVE MONEY OF THE 2 1 1 1 2 2

このように各単語の出現数がカウントされて出力されるわけです。
実際の使用例
地域サービス事業部では、Hadoopをログ解析、クローラやデータ解析などに使っていますが、日々のちょっとした業務でも活躍しています。例えば、大量のデータの中から、ランダムに10000件抽出したいなんてことがありました。これをどうMapReduceで処理するか考えてみます。
ランダムに行の数字を選び出して、その数字の行だけを出力して・・・と考えていくと難しく感じますが、
Shuffleのキー順ソートを利用して、ランダムソートしてしまえばいいわけです。

こんな入力データがあるとすると、keyにランダムな数字、valueに入力行を割り当てます。
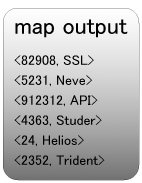
Shuffleで、キー順にソートされます。(オプションを指定して数値順にすることもできます)
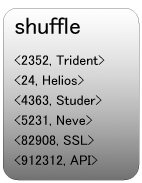
Reduceで、Valueをそのまま出力します。

あとはMapReduceの結果を、head -10000なりで取り出せば、ランダムサンプリングができます。
MapReduceの魅力
MapReduceは割り切ったモデルですが、その分プログラマーにはわかりやすいですし、
複数のMapReduceを組み合わせることで、かなり複雑な処理も行うこともできます。
必ずしもMapとReduceを組み合わせる必要はなく、Mapのみを使うことも可能、ということもポイントです。
例えば、大量の画像のフォーマットを変換したい、といった場合は、Mapだけを利用して画像の変換処理を書きます。
Shuffleのソート処理や、Reduceで同じキーをまとめてさらに処理が必要である場合以外は、Mapだけで処理を行うのがよいと思います。
MapReduceは、CouchDBでは、クエリ言語に代わるものとして採用されており、Greenplumというデータウェアハウスプラットフォームにも採用されるなど、
徐々に広がりを見せはじめています。
終わりに
Hadoopは、「高度な知識が必要」とか、「100台以上じゃないと効果が実感できない」とか、「Yahoo!ぐらい巨大なデータを扱う所じゃないと意味がない」など、
誤解をされているように感じます。
しかし、Hadoopは、面倒な分散処理を、プログラマが「簡単に」扱えることを目的としたプラットフォームです。
何時間かかかるようなデータ処理を日常的に行っている方は、是非Hadoopの導入を検討してみてください。
まずは、2〜3台からでも、効果を実感できると思います。
関連記事
Hadoopを使いこなす(1)(2010/2/1追記)
Hadoopを使いこなす(2)(2010/3/1追記)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



